Betrachten Sie die folgende AdventureWorks-Abfrage, die Transaktions-IDs der Verlaufstabelle für die Produkt-ID 421 zurückgibt:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Der Abfrageoptimierer findet schnell einen effizienten Ausführungsplan mit einer Kardinalitätsschätzung (Zeilenzahl), die genau richtig ist, wie im SQL Sentry Plan Explorer gezeigt:

Angenommen, wir möchten Verlaufstransaktions-IDs für das AdventureWorks-Produkt mit dem Namen „Metal Plate 2“ finden. Es gibt viele Möglichkeiten, diese Abfrage in T-SQL auszudrücken. Eine natürliche Formulierung ist:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Der Ausführungsplan lautet wie folgt:
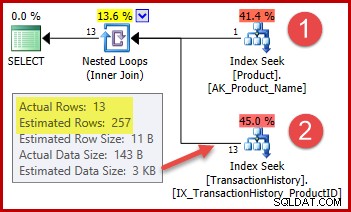
Die Strategie lautet:
- Suchen Sie die Produkt-ID in der Produkttabelle anhand des angegebenen Namens
- Suchen Sie Zeilen für diese Produkt-ID in der Verlaufstabelle
Die geschätzte Anzahl der Zeilen für Schritt 1 ist genau richtig, da der verwendete Index als eindeutig deklariert und nur auf den Produktnamen bezogen ist. Der Gleichheitstest auf "Metal Plate 2" gibt daher garantiert genau eine Zeile zurück (oder null Zeilen, wenn wir einen nicht existierenden Produktnamen angeben).
Die hervorgehobene 257-Zeilen-Schätzung für Schritt zwei ist weniger genau:Es werden tatsächlich nur 13 Zeilen angetroffen. Diese Diskrepanz entsteht, weil der Optimierer nicht weiß, welche bestimmte Produkt-ID dem Produkt mit dem Namen "Metallplatte 2" zugeordnet ist. Es behandelt den Wert als unbekannt und generiert eine Kardinalitätsschätzung unter Verwendung von Informationen zur durchschnittlichen Dichte. Die Berechnung verwendet Elemente aus dem unten gezeigten Statistikobjekt:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
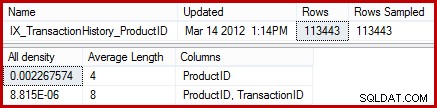
Die Statistik zeigt, dass die Tabelle 113443 Zeilen mit 441 eindeutigen Produkt-IDs enthält (1 / 0,002267574 =441). Unter der Annahme, dass die Verteilung der Zeilen über die Produkt-IDs gleichmäßig ist, erwartet die Kardinalitätsschätzung, dass eine Produkt-ID übereinstimmt (113443 / 441) =257,24 Zeilen im Durchschnitt. Wie sich herausstellt, ist die Verteilung nicht besonders gleichmäßig; Für das Produkt "Metal Plate 2" gibt es nur 13 Zeilen.
Nebenbei
Sie denken vielleicht, dass die 257-Zeilen-Schätzung genauer sein sollte. Da beispielsweise sowohl Produkt-IDs als auch Namen auf Eindeutigkeit beschränkt sind, könnte SQL Server automatisch Informationen über diese Eins-zu-Eins-Beziehung verwalten. Es wüsste dann, dass „Metallplatte 2“ der Produkt-ID 479 zugeordnet ist, und nutzte diese Erkenntnis, um mithilfe des ProductID-Histogramms eine genauere Schätzung zu erstellen:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
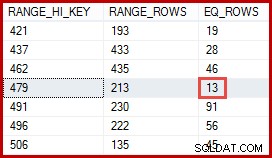
Eine auf diese Weise abgeleitete Schätzung von 13 Zeilen wäre genau richtig gewesen. Dennoch war die Schätzung von 257 Zeilen angesichts der verfügbaren statistischen Informationen und der üblichen vereinfachenden Annahmen (wie der Gleichverteilung), die heute bei der Kardinalitätsschätzung angewendet werden, nicht unangemessen. Genaue Schätzungen sind immer nett, aber "angemessene" Schätzungen sind auch vollkommen akzeptabel.
Kombinieren der beiden Abfragen
Angenommen, wir möchten jetzt alle IDs des Transaktionsverlaufs anzeigen, bei denen die Produkt-ID 421 ist OR Der Name des Produkts lautet "Metal Plate 2". Eine natürliche Möglichkeit, die beiden vorherigen Abfragen zu kombinieren, ist:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Der Ausführungsplan ist jetzt etwas komplexer, enthält aber immer noch erkennbare Elemente der Einzelprädikatpläne:
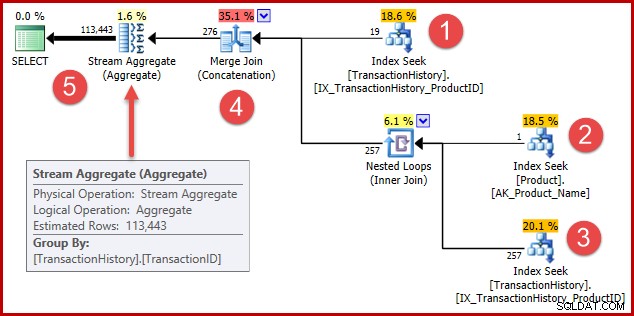
Die Strategie lautet:
- Verlaufsdatensätze für Produkt 421 finden
- Suchen Sie die Produkt-ID für das Produkt mit dem Namen "Metallplatte 2"
- Verlaufsdatensätze für die in Schritt 2 gefundene Produkt-ID finden
- Kombinieren Sie die Zeilen aus den Schritten 1 und 3
- Entfernen Sie alle Duplikate (weil Produkt 421 auch "Metal Plate 2" heißen könnte)
Die Schritte 1 bis 3 sind genau die gleichen wie zuvor. Dieselben Schätzungen werden aus denselben Gründen erstellt. Schritt 4 ist neu, aber sehr einfach:Er verkettet erwartete 19 Zeilen mit erwarteten 257 Zeilen, um eine Schätzung von 276 Zeilen zu erhalten.
Schritt 5 ist der interessanteste. Das Stream Aggregate zum Entfernen von Duplikaten hat eine geschätzte Eingabe von 276 Zeilen und eine geschätzte Ausgabe von 113443 Zeilen. Ein Aggregat, das mehr Zeilen ausgibt, als es empfängt, scheint unmöglich, oder?
* Sie sehen hier eine Schätzung von 102099 Zeilen, wenn Sie das Kardinalitätsschätzungsmodell vor 2014 verwenden.
Der Fehler bei der Kardinalitätsschätzung
Die unmögliche Stream Aggregate-Schätzung in unserem Beispiel wird durch einen Fehler in der Kardinalitätsschätzung verursacht. Es ist ein interessantes Beispiel, also werden wir es ein wenig genauer untersuchen.
Entfernung von Unterabfragen
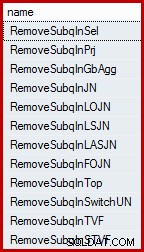
Es mag Sie überraschen, dass der SQL Server-Abfrageoptimierer nicht direkt mit Unterabfragen arbeitet. Sie werden früh im Kompilierungsprozess aus dem logischen Abfragebaum entfernt und durch eine äquivalente Konstruktion ersetzt, mit der der Optimierer arbeiten und darüber nachdenken kann. Der Optimierer verfügt über eine Reihe von Regeln, die Unterabfragen entfernen. Diese können mit der folgenden Abfrage nach Namen aufgelistet werden (die referenzierte DMV ist minimal dokumentiert, wird aber nicht unterstützt):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Ergebnisse (auf SQL Server 2014):
Die kombinierte Testabfrage hat zwei Prädikate ("Auswahlen" in relationalen Begriffen) in der Verlaufstabelle, die durch OR verbunden sind . Eines dieser Prädikate enthält eine Unterabfrage. Der gesamte Teilbaum (beide Prädikate und die Unterabfrage) wird durch die erste Regel in der Liste ("Unterabfrage in Auswahl entfernen") in einen Semi-Join über die Vereinigung der einzelnen Prädikate umgewandelt. Es ist zwar nicht möglich, das Ergebnis dieser internen Transformation genau mit der T-SQL-Syntax darzustellen, aber es kommt ziemlich nahe an:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Es ist ein wenig unglücklich, dass meine T-SQL-Annäherung des internen Baums nach dem Entfernen der Unterabfrage eine Unterabfrage enthält, aber in der Sprache des Abfrageprozessors nicht (es ist ein Semi-Join). Wenn Sie es vorziehen, die rohe interne Form anstelle meines Versuchs eines T-SQL-Äquivalents zu sehen, seien Sie bitte versichert, dass dies in Kürze verfügbar sein wird.
Der im obigen T-SQL enthaltene undokumentierte Abfragehinweis dient dazu, eine nachfolgende Transformation für diejenigen unter Ihnen zu verhindern, die die transformierte Logik in Form eines Ausführungsplans sehen möchten. Die folgenden Anmerkungen zeigen die Positionen der beiden Prädikate nach der Transformation:
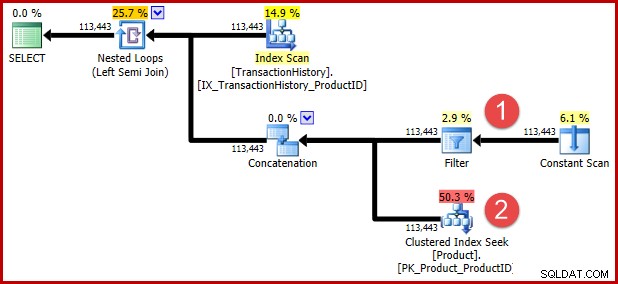
Die Intuition hinter der Transformation ist, dass eine Verlaufszeile qualifiziert ist, wenn eines der Prädikate erfüllt ist. Unabhängig davon, wie hilfreich Sie meine ungefähre Darstellung von T-SQL und Ausführungsplan finden, hoffe ich, dass zumindest einigermaßen klar ist, dass die Neufassung die gleiche Anforderung wie die ursprüngliche Abfrage ausdrückt.
Ich sollte betonen, dass der Optimierer nicht buchstäblich eine alternative T-SQL-Syntax generiert oder vollständige Ausführungspläne in Zwischenstufen erstellt. Die obigen T-SQL- und Ausführungsplandarstellungen sind lediglich als Verständnishilfe gedacht. Wenn Sie an den reinen Details interessiert sind, ist die versprochene interne Darstellung des transformierten Abfragebaums (leicht bearbeitet für Klarheit/Leerraum):
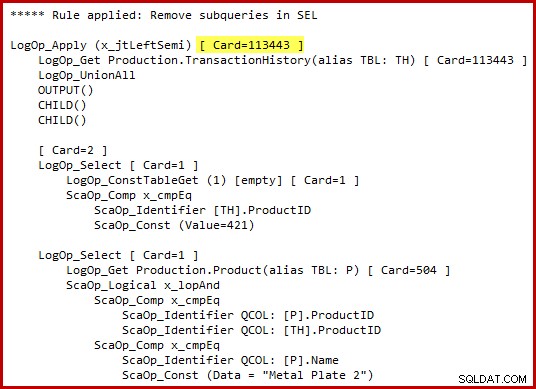
Beachten Sie die hervorgehobene Kardinalitätsschätzung „Semi Join anwenden“. Es sind 113443 Zeilen bei Verwendung des Kardinalitätsschätzers von 2014 (102099 Zeilen bei Verwendung des alten CE). Denken Sie daran, dass die AdventureWorks-Verlaufstabelle insgesamt 113443 Zeilen enthält, was eine Selektivität von 100 % darstellt (90 % für das alte CE).
Wir haben bereits gesehen, dass die alleinige Anwendung eines dieser Prädikate nur zu einer kleinen Anzahl von Übereinstimmungen führt:19 Zeilen für die Produkt-ID 421 und 13 Zeilen (geschätzt 257) für „Metal Plate 2“. Schätzen, dass die Disjunktion (OR) der beiden Prädikate alle Zeilen in der Basistabelle zurückgeben, scheint völlig verrückt zu sein.
Fehlerdetails
Die Details der Selektivitätsberechnung für den Semi-Join sind nur in SQL Server 2014 sichtbar, wenn der neue Kardinalitätsschätzer mit dem (undokumentierten) Ablaufverfolgungsflag 2363 verwendet wird. Es ist wahrscheinlich möglich, etwas Ähnliches mit erweiterten Ereignissen zu sehen, aber die Ausgabe des Ablaufverfolgungsflags ist bequemer hier zu verwenden. Der relevante Abschnitt der Ausgabe ist unten dargestellt:
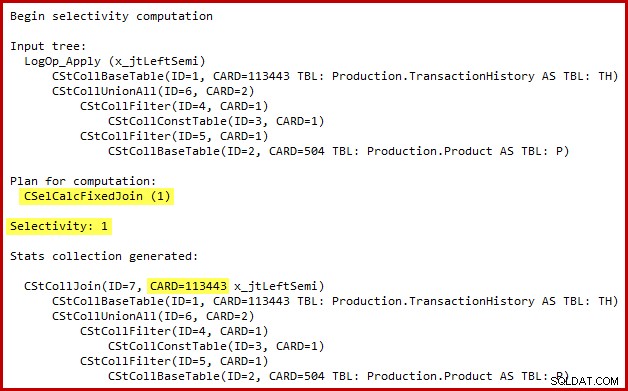
Der Kardinalitätsschätzer verwendet den Fixed Join-Rechner mit 100 % Selektivität. Folglich ist die geschätzte Ausgabekardinalität des Semi-Joins dieselbe wie seine Eingabe, was bedeutet, dass alle 113443 Zeilen aus der Verlaufstabelle voraussichtlich qualifiziert sind.
Die genaue Art des Fehlers besteht darin, dass bei der Semi-Join-Selektivitätsberechnung alle Prädikate übersehen werden, die jenseits einer Union all im Eingabebaum positioniert sind. In der folgenden Abbildung wird das Fehlen von Prädikaten für den Semi-Join selbst so verstanden, dass jede Zeile qualifiziert wird; es ignoriert die Wirkung von Prädikaten unterhalb der Verkettung (union all).
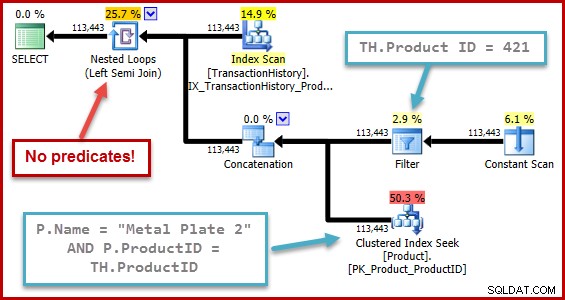
Dieses Verhalten ist umso überraschender, wenn man bedenkt, dass die Selektivitätsberechnung mit einer Baumdarstellung arbeitet, die der Optimierer selbst generiert hat (die Form des Baums und die Positionierung der Prädikate sind das Ergebnis des Entfernens der Unterabfrage).
Ein ähnliches Problem tritt beim Kardinalitätsschätzer vor 2014 auf, aber die endgültige Schätzung ist stattdessen auf 90 % der geschätzten Semi-Join-Eingabe festgelegt (aus unterhaltsamen Gründen im Zusammenhang mit einer umgekehrten festen 10 %-Prädikatschätzung, die eine zu große Ablenkung darstellt, um sie zu erhalten in).
Beispiele
Wie oben erwähnt, manifestiert sich dieser Fehler, wenn eine Schätzung für einen Semi-Join mit verwandten Prädikaten durchgeführt wird, die hinter einem Union all positioniert sind. Ob diese interne Anordnung während der Abfrageoptimierung auftritt, hängt von der ursprünglichen T-SQL-Syntax und der genauen Reihenfolge der internen Optimierungsoperationen ab. Die folgenden Beispiele zeigen einige Fälle, in denen der Fehler auftritt und nicht auftritt:
Beispiel 1
Dieses erste Beispiel enthält eine triviale Änderung an der Testabfrage:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Der geschätzte Ausführungsplan lautet:
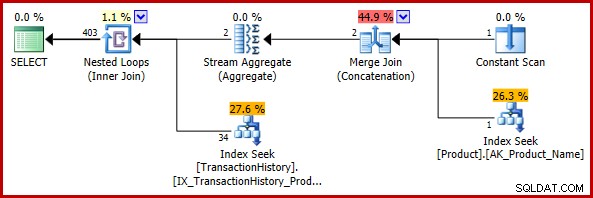
Die endgültige Schätzung von 403 Zeilen stimmt nicht mit den Eingabeschätzungen des Joins mit verschachtelten Schleifen überein, ist aber immer noch vernünftig (in dem zuvor besprochenen Sinne). Wenn der Fehler aufgetreten wäre, wäre die endgültige Schätzung 113443 Zeilen (oder 102099 Zeilen bei Verwendung des Modells vor 2014 CE).
Beispiel 2
Falls Sie gerade dabei waren, all Ihre konstanten Vergleiche als triviale Unterabfragen neu zu schreiben, um diesen Fehler zu vermeiden, sehen Sie sich an, was passiert, wenn wir eine weitere triviale Änderung vornehmen und diesmal den Gleichheitstest im zweiten Prädikat durch IN ersetzen. Die Bedeutung der Abfrage bleibt unverändert:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Der Fehler gibt zurück:
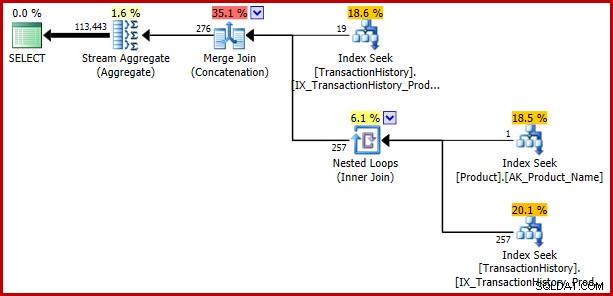
Beispiel 3
Obwohl sich dieser Artikel bisher auf ein disjunktives Prädikat konzentriert hat, das eine Unterabfrage enthält, zeigt das folgende Beispiel, dass dieselbe Abfragespezifikation, die mit EXISTS und UNION ALL ausgedrückt wird, ebenfalls anfällig ist:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Ausführungsplan:
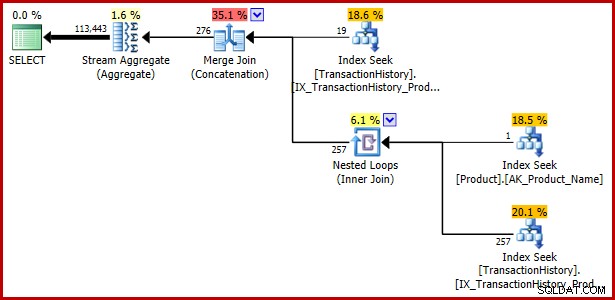
Beispiel 4
Hier sind zwei weitere Möglichkeiten, dieselbe logische Abfrage in T-SQL auszudrücken:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Keine der Abfragen trifft auf den Fehler, und beide erzeugen denselben Ausführungsplan:
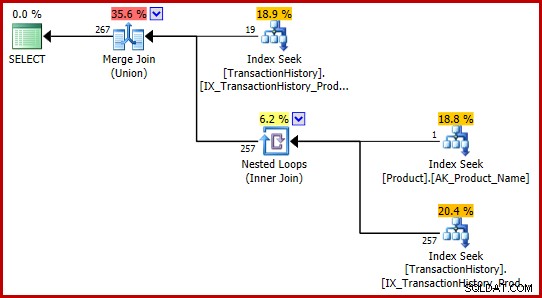
Diese T-SQL-Formulierungen erzeugen zufällig einen Ausführungsplan mit vollständig konsistenten (und vernünftigen) Schätzungen.
Beispiel 5
Sie fragen sich vielleicht, ob die ungenaue Schätzung wichtig ist. In den bisher vorgestellten Fällen ist dies nicht der Fall, zumindest nicht direkt. Probleme treten auf, wenn der Fehler in einer größeren Abfrage auftritt und die falsche Schätzung die Entscheidungen des Optimierers an anderer Stelle beeinflusst. Als minimal erweitertes Beispiel können Sie die Ergebnisse unserer Testabfrage in zufälliger Reihenfolge zurückgeben:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Der Ausführungsplan zeigt, dass sich die falsche Schätzung auf spätere Operationen auswirkt. Beispielsweise ist es die Grundlage für die Speicherzuteilung, die für die Sortierung reserviert ist:
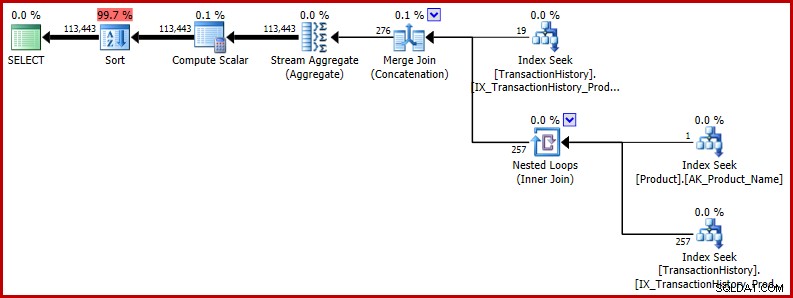
Wenn Sie ein realistischeres Beispiel für die potenziellen Auswirkungen dieses Fehlers sehen möchten, werfen Sie einen Blick auf diese aktuelle Frage von Richard Mansell auf der Q&A-Website von SQLPerformance.com, answers.SQLPerformance.com.
Zusammenfassung und abschließende Gedanken
Dieser Fehler wird ausgelöst, wenn der Optimierer unter bestimmten Umständen eine Kardinalitätsschätzung für einen Semi-Join durchführt. Es ist aus mehreren Gründen schwierig, diesen Fehler zu erkennen und zu umgehen:
- Es gibt keine explizite T-SQL-Syntax, um einen Semi-Join anzugeben, daher ist es schwierig, im Voraus zu wissen, ob eine bestimmte Abfrage für diesen Fehler anfällig ist.
- Der Optimierer kann einen Semi-Join in einer Vielzahl von Situationen einführen, von denen nicht alle offensichtliche Semi-Join-Kandidaten sind.
- Der problematische Semi-Join wird oft durch spätere Optimierungsaktivitäten in etwas anderes umgewandelt, sodass wir uns nicht einmal darauf verlassen können, dass es im endgültigen Ausführungsplan eine Semi-Join-Operation gibt.
- Nicht jede seltsam aussehende Kardinalitätsschätzung wird durch diesen Fehler verursacht. Tatsächlich sind viele Beispiele dieser Art ein erwarteter und harmloser Nebeneffekt des normalen Optimiererbetriebs.
- Die fehlerhafte Semi-Join-Selektivitätsschätzung beträgt immer 90 % oder 100 % der Eingabe, aber dies entspricht normalerweise nicht der Kardinalität einer im Plan verwendeten Tabelle. Darüber hinaus ist die in der Berechnung verwendete Semi-Join-Eingabekardinalität möglicherweise nicht einmal im endgültigen Ausführungsplan sichtbar.
- In der Regel gibt es viele Möglichkeiten, dieselbe logische Abfrage in T-SQL auszudrücken. Einige davon lösen den Fehler aus, andere nicht.
Diese Überlegungen machen es schwierig, praktische Ratschläge zu geben, um diesen Fehler zu erkennen oder zu umgehen. Es lohnt sich sicherlich, Ausführungspläne auf "unerhörte" Schätzungen zu überprüfen und Abfragen mit einer Leistung zu untersuchen, die viel schlechter als erwartet ist, aber beides kann Ursachen haben, die nicht mit diesem Fehler zusammenhängen. Allerdings lohnt es sich besonders, Abfragen zu prüfen, die eine Disjunktion von Prädikaten und eine Unterabfrage enthalten. Wie die Beispiele in diesem Artikel zeigen, ist dies nicht die einzige Möglichkeit, auf den Fehler zu stoßen, aber ich gehe davon aus, dass er häufig vorkommt.
Wenn Sie das Glück haben, SQL Server 2014 mit aktiviertem neuen Kardinalitätsschätzer auszuführen, können Sie den Fehler möglicherweise bestätigen, indem Sie die Ausgabe des Ablaufverfolgungsflags 2363 manuell auf eine feste Schätzung der Selektivität von 100 % bei einem Semi-Join überprüfen, aber das ist es kaum bequem. Sie werden natürlich keine undokumentierten Trace-Flags auf einem Produktionssystem verwenden wollen.
Den User Voice-Fehlerbericht zu diesem Problem finden Sie hier. Bitte stimmen Sie ab und kommentieren Sie, wenn Sie möchten, dass dieses Problem untersucht (und möglicherweise behoben) wird.