In einer perfekten Welt wäre es egal, welche spezielle T-SQL-Syntax wir wählen, um eine Abfrage auszudrücken. Jede semantisch identische Konstruktion würde zu genau demselben physischen Ausführungsplan mit genau denselben Leistungsmerkmalen führen.
Um dies zu erreichen, müsste der SQL Server-Abfrageoptimierer jede mögliche logische Äquivalenz kennen (vorausgesetzt, wir könnten sie alle kennen) und die Zeit und Ressourcen erhalten, um alle Optionen zu untersuchen. Angesichts der enormen Anzahl möglicher Möglichkeiten, dieselbe Anforderung in T-SQL auszudrücken, und der enormen Anzahl möglicher Transformationen werden die Kombinationen für alle außer den einfachsten Fällen schnell unhandlich.
Eine "perfekte Welt" mit vollständiger Syntaxunabhängigkeit mag Benutzern, die Tage, Wochen oder sogar Jahre auf die Kompilierung einer bescheiden komplexen Abfrage warten müssen, nicht ganz so perfekt erscheinen. Der Abfrageoptimierer geht also Kompromisse ein:Er untersucht einige allgemeine Äquivalenzen und bemüht sich, nicht mehr Zeit für die Kompilierung und Optimierung aufzuwenden, als er an Ausführungszeit spart. Sein Ziel lässt sich so zusammenfassen, dass versucht wird, in angemessener Zeit einen vernünftigen Ausführungsplan zu finden und dabei angemessene Ressourcen zu verbrauchen.
Ein Ergebnis all dessen ist, dass Ausführungspläne oft empfindlich auf die schriftliche Form der Abfrage reagieren. Der Optimierer verfügt zwar über eine gewisse Logik, um einige weit verbreitete äquivalente Konstruktionen schnell in eine gemeinsame Form umzuwandeln, aber diese Fähigkeiten sind weder gut dokumentiert noch (annähernd) umfassend.
Wir können unsere Chancen auf einen guten Ausführungsplan sicherlich maximieren, indem wir einfachere Abfragen schreiben, nützliche Indizes bereitstellen, gute Statistiken pflegen und uns auf relationalere Konzepte beschränken (z. B. indem wir Cursor, explizite Schleifen und nicht inline Funktionen vermeiden), aber das ist es keine Komplettlösung. Es ist auch nicht möglich zu sagen, dass eine T-SQL-Konstruktion immer funktioniert einen besseren Ausführungsplan erstellen als eine semantisch identische Alternative.
Mein üblicher Rat ist, mit der einfachsten relationalen Abfrageform zu beginnen, die Ihren Anforderungen entspricht, und die T-SQL-Syntax zu verwenden, die Sie bevorzugen. Wenn die Abfrage nach der physischen Optimierung (z. B. Indizierung) nicht den Anforderungen entspricht, kann es sich lohnen, die Abfrage etwas anders auszudrücken und dabei die ursprüngliche Semantik beizubehalten. Dies ist der schwierige Teil. Welchen Teil der Abfrage sollten Sie versuchen umzuschreiben? Welche Umschreibung sollten Sie versuchen? Auf diese Fragen gibt es keine pauschale Antwort. Einiges davon hängt von der Erfahrung ab, obwohl ein wenig Wissen über die Abfrageoptimierung und die Interna der Ausführungs-Engine ebenfalls ein nützlicher Leitfaden sein kann.
Beispiel
In diesem Beispiel wird die Tabelle AdventureWorks TransactionHistory verwendet. Das folgende Skript erstellt eine Kopie der Tabelle und erstellt einen gruppierten und einen nicht gruppierten Index. Wir werden die Daten überhaupt nicht ändern; Dieser Schritt dient nur dazu, die Indexierung klarer zu machen (und der Tabelle einen kürzeren Namen zu geben):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Die Aufgabe besteht darin, eine Liste von Produkt- und Historien-IDs für sechs bestimmte Produkte zu erstellen. Eine Möglichkeit, die Abfrage auszudrücken, ist:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Diese Abfrage gibt 764 Zeilen zurück, wobei der folgende Ausführungsplan verwendet wird (im SentryOne-Plan-Explorer angezeigt):

Diese einfache Abfrage qualifiziert sich für die TRIVIAL-Plankompilierung. Der Ausführungsplan enthält sechs separate Indexsuchoperationen in einer:
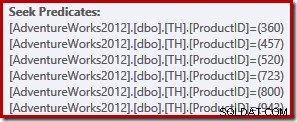
Scharfäugige Leser werden bemerkt haben, dass die sechs Suchvorgänge aufsteigend aufgelistet sind Produkt-ID-Reihenfolge, nicht in der (beliebigen) Reihenfolge, die in der IN-Liste der ursprünglichen Abfrage angegeben ist. Wenn Sie die Abfrage selbst ausführen, werden Sie sehr wahrscheinlich feststellen, dass die Ergebnisse in aufsteigender Reihenfolge der Produkt-IDs zurückgegeben werden. Die Abfrage ist nicht garantiert Ergebnisse natürlich in dieser Reihenfolge zurückzugeben, da wir keine ORDER BY-Klausel der obersten Ebene angegeben haben. Wir können jedoch eine solche ORDER BY-Klausel hinzufügen, ohne den in diesem Fall erzeugten Ausführungsplan zu ändern:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Ich werde die Grafik des Ausführungsplans nicht wiederholen, da sie genau gleich ist:Die Abfrage qualifiziert sich immer noch für einen trivialen Plan, die Suchoperationen sind genau gleich und die beiden Pläne haben genau die gleichen geschätzten Kosten. Das Hinzufügen der ORDER BY-Klausel hat uns genau nichts gekostet, aber uns eine Garantie für die Sortierung der Ergebnismenge verschafft.
Wir haben jetzt eine Garantie, dass die Ergebnisse in der Reihenfolge der Produkt-IDs zurückgegeben werden, aber unsere Abfrage gibt derzeit nicht an, wie Zeilen mit dem gleichen Produkt-ID wird bestellt. Wenn Sie sich die Ergebnisse ansehen, stellen Sie möglicherweise fest, dass Zeilen für dieselbe Produkt-ID aufsteigend nach Transaktions-ID sortiert zu sein scheinen.
Ohne explizites ORDER BY ist dies nur eine weitere Beobachtung (d. h. wir können uns nicht auf diese Reihenfolge verlassen), aber wir können die Abfrage ändern, um sicherzustellen, dass die Zeilen innerhalb jeder Produkt-ID nach Transaktions-ID geordnet sind:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Auch hier ist der Ausführungsplan für diese Abfrage genau derselbe wie zuvor; es wird der gleiche triviale Plan mit den gleichen geschätzten Kosten erstellt. Der Unterschied besteht darin, dass die Ergebnisse jetzt garantiert sind zuerst nach Produkt-ID und dann nach Transaktions-ID sortiert werden.
Einige Leute könnten versucht sein zu schlussfolgern, dass die beiden vorherigen Abfragen ebenfalls immer Zeilen in dieser Reihenfolge zurückgeben würden, da die Ausführungspläne dieselben sind. Dies ist keine sichere Implikation, da nicht alle Details der Ausführungsengine in Ausführungsplänen offengelegt werden (selbst im XML-Formular). Ohne eine explizite order by-Klausel kann SQL Server die Zeilen in beliebiger Reihenfolge zurückgeben, selbst wenn der Plan für uns gleich aussieht (er könnte beispielsweise die Suchvorgänge in der im Abfragetext angegebenen Reihenfolge ausführen). Der Punkt ist, dass der Abfrageoptimierer bestimmte Verhaltensweisen innerhalb der Engine, die für Benutzer nicht sichtbar sind, kennt und erzwingen kann.
Falls Sie sich fragen, wie unser nicht eindeutiger, nicht gruppierter Index für Produkt-ID Zeilen in Produkt und zurückgeben kann In der Reihenfolge der Transaktions-ID lautet die Antwort, dass der Nonclustered-Indexschlüssel die Transaktions-ID (den eindeutigen Clustered-Indexschlüssel) enthält. Tatsächlich das physische Die Struktur unseres Nonclustered-Index ist genau auf allen Ebenen gleich, als ob wir den Index mit der folgenden Definition erstellt hätten:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Wir können die Abfrage sogar mit einem expliziten DISTINCT oder GROUP BY schreiben und erhalten immer noch genau denselben Ausführungsplan:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Um es deutlich zu machen, erfordert dies keine Änderung des ursprünglichen Nonclustered-Index in irgendeiner Weise. Beachten Sie als letztes Beispiel, dass wir Ergebnisse auch in absteigender Reihenfolge anfordern können:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Die Eigenschaften des Ausführungsplans zeigen jetzt, dass der Index rückwärts gescannt wird:

Abgesehen davon ist der Plan derselbe – er wurde in der trivialen Planoptimierungsphase erstellt und hat immer noch die gleichen geschätzten Kosten.
Umschreiben der Abfrage
An der vorherigen Abfrage oder dem Ausführungsplan ist nichts auszusetzen, aber wir haben uns vielleicht entschieden, die Abfrage anders auszudrücken:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Dieses Formular gibt eindeutig genau dieselben Ergebnisse wie das Original an, und die neue Abfrage erzeugt tatsächlich denselben Ausführungsplan (trivialer Plan, mehrere Suchvorgänge in einem, dieselben geschätzten Kosten). Das ODER-Formular macht vielleicht etwas klarer, dass das Ergebnis eine Kombination der Ergebnisse für die sechs einzelnen Produkt-IDs ist, was uns dazu veranlassen könnte, eine andere Variante auszuprobieren, die diese Idee noch deutlicher macht:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Der Ausführungsplan für die UNION ALL-Abfrage ist ganz anders:
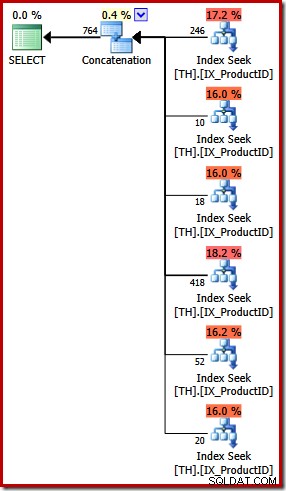
Abgesehen von den offensichtlichen visuellen Unterschieden erforderte dieser Plan eine kostenbasierte (VOLLSTÄNDIGE) Optimierung (er qualifiziert sich nicht für einen trivialen Plan), und die geschätzten Kosten sind (relativ gesehen) um einiges höher, etwa 0,02 Einheiten gegenüber etwa 0,005 Einheiten vor.
Dies geht auf meine einleitenden Bemerkungen zurück:Der Abfrageoptimierer kennt nicht jede logische Äquivalenz und kann nicht immer erkennen, dass alternative Abfragen dieselben Ergebnisse angeben. Der Punkt, den ich an dieser Stelle hervorheben möchte, ist, dass das Ausdrücken dieser speziellen Abfrage mit UNION ALL anstelle von IN zu einem weniger optimalen Ausführungsplan führte.
Zweites Beispiel
Dieses Beispiel wählt einen anderen Satz von sechs Produkt-IDs und fordert Ergebnisse in der Reihenfolge der Transaktions-IDs an:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Unser Nonclustered-Index kann keine Zeilen in der angeforderten Reihenfolge bereitstellen, daher hat der Abfrageoptimierer die Wahl zwischen dem Suchen im Nonclustered-Index und Sortieren oder dem Scannen des Clustered-Index (der nur auf der Transaktions-ID basiert) und dem Anwenden der Produkt-ID-Prädikate als ein Rest. Die aufgelisteten Produkt-IDs haben zufällig eine geringere Selektivität als der vorherige Satz, daher wählt der Optimierer in diesem Fall einen Clustered-Index-Scan:
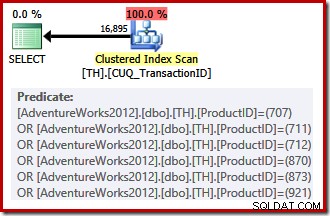
Da eine kostenbasierte Wahl getroffen werden muss, kam dieser Ausführungsplan nicht als trivialer Plan infrage. Die geschätzten Kosten des endgültigen Plans betragen etwa 0,714 Einheiten. Das Scannen des gruppierten Index erfordert 797 logische Lesevorgänge zur Ausführungszeit.
Vielleicht überrascht, dass die Abfrage den Produktindex nicht verwendet hat, könnten wir versuchen, eine Suche nach dem Nonclustered-Index zu erzwingen, indem wir einen Indexhinweis verwenden oder FORCESEEK:
angebenSELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
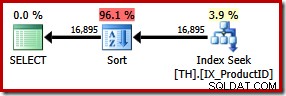
Dies führt zu einer expliziten Sortierung nach Transaktions-ID. Die neue Sorte wird auf 96 % geschätzt des neuen Plans 1.15 Kosten pro Einheit. Diese höheren geschätzten Kosten erklären, warum der Optimierer den scheinbar billigeren Clustered-Index-Scan gewählt hat, als er sich selbst überlassen war. Die E/A-Kosten der neuen Abfrage sind jedoch niedriger:Bei der Ausführung verbraucht die Indexsuche nur 49 logische Lesevorgänge (von 797).
Wir könnten uns auch dafür entschieden haben, diese Abfrage mit der (vorher erfolglosen) UNION ALL-Idee auszudrücken:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Das erzeugt den folgenden Ausführungsplan (klicken Sie auf das Bild, um es in einem neuen Fenster zu vergrößern):

Dieser Plan mag komplexer erscheinen, hat aber geschätzte Kosten von nur 0,099 Einheiten, was viel niedriger ist als der Clustered-Index-Scan (0,714 Einheiten) oder Suchen plus Sortieren (1.15 Einheiten). Darüber hinaus verbraucht der neue Plan nur 49 logische Lesevorgänge zur Ausführungszeit – dasselbe wie beim Seek + Sort-Plan und viel weniger als die 797, die für den Clustered-Index-Scan benötigt werden.
Diesmal führte das Ausdrücken der Abfrage mit UNION ALL zu einem viel besseren Plan, sowohl in Bezug auf die geschätzten Kosten als auch auf logische Lesevorgänge. Der Quelldatensatz ist etwas zu klein, um einen wirklich aussagekräftigen Vergleich zwischen der Abfragedauer oder der CPU-Auslastung anzustellen, aber der Clustered-Index-Scan dauert doppelt so lange (26 ms) wie die anderen beiden auf meinem System.
Die zusätzliche Sortierung im angedeuteten Plan ist in diesem einfachen Beispiel wahrscheinlich harmlos, da es unwahrscheinlich ist, dass sie auf die Festplatte übertragen wird, aber viele Leute werden den UNION ALL-Plan trotzdem bevorzugen, da er nicht blockiert, eine Speicherzuweisung vermeidet und keine erfordert Abfragehinweis.
Schlussfolgerung
Wir haben gesehen, dass die Abfragesyntax den vom Optimierer gewählten Ausführungsplan beeinflussen kann, obwohl die Abfragen logischerweise genau dieselbe Ergebnismenge angeben. Dasselbe Umschreiben (z. B. UNION ALL) führt manchmal zu einer Verbesserung und manchmal dazu, dass ein schlechterer Plan ausgewählt wird.
Das Umschreiben von Abfragen und das Ausprobieren alternativer Syntax ist eine gültige Optimierungstechnik, aber es ist einige Sorgfalt erforderlich. Ein Risiko besteht darin, dass zukünftige Änderungen am Produkt dazu führen könnten, dass das andere Abfrageformular plötzlich nicht mehr den besseren Plan produziert, aber man könnte argumentieren, dass dies immer ein Risiko ist und durch Tests vor dem Upgrade oder die Verwendung von Planleitfäden gemildert wird.
Es besteht auch die Gefahr, dass Sie sich von dieser Technik mitreißen lassen:Die Verwendung von "seltsamen" oder "ungewöhnlichen" Abfragekonstruktionen, um einen Plan mit besserer Leistung zu erhalten, ist oft ein Zeichen dafür, dass eine Grenze überschritten wurde. Wo genau die Unterscheidung zwischen gültiger alternativer Syntax und „ungewöhnlich/seltsam“ liegt, ist wahrscheinlich ziemlich subjektiv; Mein persönlicher Leitfaden ist, mit gleichwertigen relationalen Abfrageformen zu arbeiten und die Dinge so einfach wie möglich zu halten.



