Für die Leistung von SQL Server verantwortlich zu sein, kann eine entmutigende Aufgabe sein. Es gibt viele Bereiche, die wir überwachen und verstehen müssen. Es wird auch erwartet, dass wir in der Lage sind, all diese Metriken im Auge zu behalten und jederzeit zu wissen, was auf unseren Servern passiert. Ich frage DBAs gerne, woran sie als Erstes denken, wenn sie den Ausdruck „Tuning von SQL Server“ hören; Die überwältigende Antwort, die ich bekomme, ist „Abfrage-Tuning“. Ich stimme zu, dass das Optimieren von Abfragen sehr wichtig und eine nie endende Aufgabe ist, der wir gegenüberstehen, da sich die Arbeitslasten ständig ändern.
Es gibt jedoch viele andere Aspekte, die bei der Betrachtung der Leistung von SQL Server berücksichtigt werden müssen. Es gibt viele Einstellungen auf Instanz-, Betriebssystem- und Datenbankebene, die von den Standardeinstellungen angepasst werden müssen. Als Beraterin kann ich in vielen verschiedenen Geschäftsbereichen arbeiten und mich mit allen möglichen Leistungsproblemen auseinandersetzen. Wenn ich mit einem neuen Client arbeite, versuche ich immer, eine Integritätsprüfung des Servers durchzuführen, um zu wissen, womit ich es zu tun habe. Bei der Durchführung dieser Audits habe ich wiederholt festgestellt, dass übermäßige Lese- und Schreiblatenzen auf den Festplatten, auf denen sich SQL Server-Daten und -Protokolldateien befinden, aufgetreten sind.
Lese-/Schreiblatenz
Um Ihre Datenträgerlatenzen in SQL Server anzuzeigen, können Sie schnell und einfach die DMV sys.dm_io_virtual_file_stats abfragen . Diese DMV akzeptiert zwei Parameter:database_id und file_id . Das Tolle ist, dass Sie NULL übergeben können als beide Werte und geben die Latenzen für alle Dateien für alle Datenbanken zurück. Die Ausgabespalten umfassen:
- Datenbank-ID
- Datei-ID
- sample_ms
- Anzahl_von_Lesungen
- num_of_bytes_read
- io_stall_read_ms
- num_of_writes
- Anzahl_der_geschriebenen_Bytes
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
Wie Sie der Spaltenliste entnehmen können, gibt es wirklich nützliche Informationen, die diese DMV abruft, jedoch führen Sie einfach SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); aus hilft nicht viel, es sei denn, Sie haben sich Ihre Datenbank-IDs gemerkt und können im Kopf etwas rechnen.
Wenn ich die Dateistatistiken abfrage, verwende ich eine Abfrage aus Paul Randals Blog-Beitrag „Wie man Latenzen von IO-Subsystemen innerhalb von SQL Server untersucht“. Dieses Skript erleichtert das Lesen der Spaltennamen, enthält das Laufwerk, auf dem sich die Datei befindet, den Datenbanknamen und den Pfad zur Datei.
Durch Abfragen dieses DMV können Sie leicht feststellen, wo sich die E/A-Hotspots für Ihre Dateien befinden. Sie können sehen, wo die höchsten Schreib- und Leselatenzen sind und welche Datenbanken die Übeltäter sind. Wenn Sie dies wissen, können Sie damit beginnen, die Tuning-Möglichkeiten für diese spezifischen Datenbanken zu untersuchen. Dies könnte die Indexoptimierung, die Überprüfung, ob der Pufferpool unter Speicherdruck steht, das mögliche Verschieben der Datenbank in einen schnelleren Teil des E/A-Subsystems oder das Partitionieren der Datenbank und das Verteilen der Dateigruppen auf andere LUNs umfassen.
Sie führen also die Abfrage aus und sie gibt viele Werte in Millisekunden für die Latenz zurück – welche Werte sind in Ordnung und welche schlecht?
Welche Werte sind gut oder schlecht?
Wenn Sie SQLskills fragen, werden wir Ihnen etwas in etwa sagen:
- Ausgezeichnet:<1ms
- Sehr gut:<5ms
- Gut:5 – 10 ms
- Schlecht:10–20 ms
- Schlecht:20 – 100 ms
- Wirklich schlecht:100 – 500 ms
- OMG!:> 500 ms
Wenn Sie eine Bing-Suche durchführen, finden Sie Artikel von Microsoft mit ähnlichen Empfehlungen wie:
- Gut:<10 ms
- Okay:10–20 ms
- Schlecht:20–50 ms
- Ernsthaft schlecht:> 50 ms
Wie Sie sehen können, gibt es einige geringfügige Abweichungen in den Zahlen, aber der Konsens ist, dass alles über 20 ms als problematisch angesehen werden kann. Abgesehen davon kann Ihre durchschnittliche Schreiblatenz 20 ms betragen, was für Ihr Unternehmen zu 100 % akzeptabel und in Ordnung ist. Sie müssen die allgemeinen E/A-Latenzen für Ihr System kennen, damit Sie wissen, was normal ist, wenn die Dinge schlecht werden.
Meine Lese-/Schreiblatenzen sind schlecht, was kann ich tun?
Wenn Sie feststellen, dass Lese- und Schreiblatenzen auf Ihrem Server schlecht sind, können Sie an mehreren Stellen nach Problemen suchen. Dies ist keine vollständige Liste, aber eine Anleitung, wo Sie anfangen sollen.
- Analysieren Sie Ihre Arbeitsbelastung. Ist Ihre Indizierungsstrategie richtig? Wenn Sie nicht über die richtigen Indizes verfügen, werden viel mehr Daten von der Festplatte gelesen. Scannt statt sucht.
- Sind Ihre Statistiken aktuell? Schlechte Statistiken können zu schlechten Entscheidungen für Ausführungspläne führen.
- Haben Sie Parameter-Sniffing-Probleme, die schlechte Ausführungspläne verursachen?
- Steht der Pufferpool unter Speicherdruck, beispielsweise durch einen aufgeblähten Plan-Cache?
- Irgendwelche Netzwerkprobleme? Funktioniert Ihr SAN-Fabric ordnungsgemäß? Lassen Sie Pfad und Netzwerk von Ihrem Speichertechniker validieren.
- Verschieben Sie die Hotspots auf andere Speicher-Arrays. In einigen Fällen kann es eine einzelne Datenbank oder nur wenige Datenbanken sein, die alle Probleme verursachen. Das Isolieren auf einem anderen Festplattensatz oder einer schnelleren High-End-Festplatte wie SSDs kann die beste logische Lösung sein.
- Können Sie die Datenbank partitionieren, um problematische Tabellen auf andere Festplatten zu verschieben, um die Last zu verteilen?
Wartestatistik
Genau wie die Überwachung Ihrer Dateistatistiken kann Ihnen die Überwachung Ihrer Wartestatistiken viel über Engpässe in Ihrer Umgebung verraten. Wir haben das Glück, ein weiteres großartiges DMV (sys.dm_os_wait_stats ), die wir abfragen können, um alle verfügbaren Warteinformationen abzurufen, die seit dem letzten Neustart oder seit dem letzten Zurücksetzen der Wartezeiten gesammelt wurden; Es gibt auch Wartezeiten im Zusammenhang mit der Festplattenleistung. Diese DMV gibt wichtige Informationen zurück, darunter:
- wait_type
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
Beim Abfragen dieser DMV auf meinem SQL Server 2014-Computer wurden 771 Wartetypen zurückgegeben. SQL Server wartet immer auf etwas, aber es gibt viele Wartezeiten, mit denen wir uns keine Sorgen machen sollten. Aus diesem Grund verwende ich eine andere Abfrage von Paul Randal; sein Blog-Beitrag „Wartestatistiken, oder sag mir bitte, wo es weh tut“ enthält ein ausgezeichnetes Skript, das eine Reihe von Wartezeiten ausschließt, die uns nicht wirklich interessieren. Paul listet auch viele der häufigsten problematischen Wartezeiten auf und bietet Anleitungen für die üblichen Wartezeiten.
Warum sind Wartestatistiken wichtig?
Die Überwachung auf hohe Wartezeiten für bestimmte Ereignisse zeigt Ihnen, wenn Probleme auftreten. Sie brauchen eine Grundlinie, um zu wissen, was normal ist und wann die Dinge eine Schwelle oder ein Schmerzniveau überschreiten. Wenn Sie sehr viel PAGEIOLATCH_XX haben dann wissen Sie, dass SQL Server warten muss, bis eine Datenseite von der Festplatte gelesen wird. Dies können Datenträger, Arbeitsspeicher, Workload-Änderungen oder eine Reihe anderer Probleme sein.
Ein neuer Kunde, mit dem ich zusammengearbeitet habe, beobachtete ein sehr ungewöhnliches Verhalten. Als ich mich mit dem Datenbankserver verbunden habe und den Server unter Arbeitslast beobachten konnte, habe ich sofort damit begonnen, Dateistatistiken, Wartestatistiken, Speichernutzung, Tempdb-Nutzung usw. zu überprüfen. Eine Sache, die sofort auffiel, war WRITELOG die am weitesten verbreitete warten. Ich weiß, dass dieses Warten mit einem Log-Flush auf die Festplatte zu tun hat und mich an Pauls Serie über das Trimmen des Transaktionsprotokolls Fat erinnert hat. Hoch WRITELOG Wartezeiten können normalerweise durch hohe Schreiblatenzen für die Transaktionsprotokolldatei identifiziert werden. Also habe ich dann mein Dateistatistikskript verwendet, um die Lese- und Schreiblatenzen auf der Festplatte zu überprüfen. Ich konnte dann eine hohe Schreiblatenz in der Datendatei sehen, aber nicht in meiner Protokolldatei. Beim Betrachten des WRITELOG Es war eine lange Wartezeit, aber die Wartezeit in Millisekunden war extrem niedrig. Allerdings war etwas im zweiten Post von Pauls Serie noch in meinem Kopf. Ich sollte mir die Einstellungen für das automatische Wachstum für die Datenbank ansehen, nur um „Tod durch tausend Schnitte“ auszuschließen. Als ich mir die Datenbankeigenschaften der Datenbank ansah, sah ich, dass die Datendatei auf automatische Vergrößerung um 1 MB und das Transaktionsprotokoll auf automatische Vergrößerung um 10 % eingestellt war. Beide Dateien hatten fast 0 ungenutzten Speicherplatz. Ich teilte dem Kunden mit, was ich gefunden habe und wie dies seine Leistung beeinträchtigte. Wir haben schnell die entsprechende Änderung vorgenommen und das Testen ging voran, übrigens viel besser. Leider ist dies nicht das einzige Mal, dass ich genau auf dieses Problem stoße. Ein anderes Mal war eine Datenbank 66 GB groß und wurde um 1 MB vergrößert.
Erfassen Ihrer Daten
Viele Datenexperten haben Prozesse entwickelt, um Dateien zu erfassen und Statistiken regelmäßig zur Analyse abzuwarten. Da die Wartestatistiken kumulativ sind, möchten Sie sie erfassen und die Deltas zwischen verschiedenen Tageszeiten oder vor und nach der Ausführung bestimmter Prozesse vergleichen. Das ist nicht allzu kompliziert und es gibt zahlreiche Blog-Beiträge, in denen Leute mitteilen, wie sie dies erreicht haben. Der wichtige Teil besteht darin, diese Daten zu messen, damit Sie sie überwachen können. Woher wissen Sie heute, dass es Ihrem Datenbankserver besser oder schlechter geht, wenn Sie nicht die Daten von gestern kennen?
Wie kann SQL Sentry helfen?
Ich bin froh, dass du gefragt hast! SQL Sentry Performance Advisor bringt Latenz und Wartezeiten im Vordergrund und in der Mitte des Dashboards. Alle Anomalien sind leicht zu erkennen; Sie können in den historischen Modus wechseln und den vorherigen Trend sehen und diesen auch mit früheren Perioden vergleichen. Dies kann sich als unbezahlbar erweisen, wenn Sie diese „Was ist passiert?“ analysieren. Momente. Jeder hat diesen Anruf erhalten:„Gestern gegen 15:00 Uhr schien das System einfach einzufrieren, können Sie uns sagen, was passiert ist?“ Ähm, sicher, lassen Sie mich den Profiler aufrufen und in der Zeit zurückgehen. Wenn Sie ein Überwachungstool wie Performance Advisor haben, haben Sie diese historischen Informationen immer zur Hand.
Zusätzlich zu den Diagrammen und Grafiken auf dem Dashboard haben Sie die Möglichkeit, integrierte Warnungen für Bedingungen wie hohe Festplattenwartezeiten, hohe VLF-Zählungen, hohe CPU, niedrige Seitenlebenserwartung und vieles mehr zu verwenden. Sie haben auch die Möglichkeit, Ihre eigenen benutzerdefinierten Bedingungen zu erstellen, und Sie können von den Beispielen auf der SQL Sentry-Site oder über den Condition Exchange lernen (Aaron Bertrand hat darüber gebloggt). Ich habe die Warnseite davon in meinem letzten Artikel über SQL Server-Agent-Warnungen angesprochen.
Auf der Registerkarte Speicherplatz des Leistungsratgebers sind Dinge wie Einstellungen für automatisches Wachstum und hohe VLF-Zählungen sehr einfach zu sehen. Sie sollten es wissen, aber falls Sie es nicht wissen, ist die automatische Vergrößerung um 1 MB oder 10 % nicht die beste Einstellung. Wenn Sie diese Werte sehen (Performance Advisor hebt sie für Sie hervor), können Sie sie schnell notieren und die Zeit für die Durchführung der richtigen Anpassungen einplanen. Ich finde es toll, wie es auch Total VLFs anzeigt; zu viele VLFs können sehr problematisch sein. Sie sollten Kimberlys Post „Transaction Log VLFs – too much or too less?“ lesen. falls noch nicht geschehen.
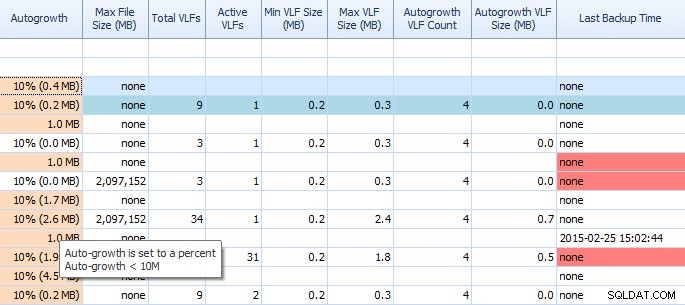 Teilraster auf der Registerkarte "Speicherplatz" des Leistungsratgebers
Teilraster auf der Registerkarte "Speicherplatz" des Leistungsratgebers
Eine weitere Möglichkeit, wie Performance Advisor helfen kann, ist das patentierte Festplattenaktivitätsmodul. Hier können Sie sehen, dass tempdb auf F:eine erhebliche Schreiblatenz aufweist; Sie können dies an den dicken roten Linien unter der Festplattengrafik erkennen. Sie werden vielleicht auch bemerken, dass F:der einzige Laufwerksbuchstabe ist, dessen Festplatte rot dargestellt wird; Dies ist ein sichtbarer Hinweis darauf, dass das Laufwerk eine falsch ausgerichtete Partition hat, was zu E/A-Problemen beitragen kann.
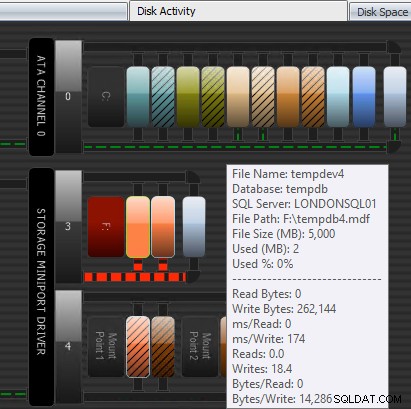 Leistungsratgeber-Festplattenaktivitätsmodul
Leistungsratgeber-Festplattenaktivitätsmodul
Und Sie können diese Informationen in den Rastern unten korrelieren – Probleme werden auch dort in den Rastern hervorgehoben, und werfen Sie einen Blick auf ms/Write Spalte:
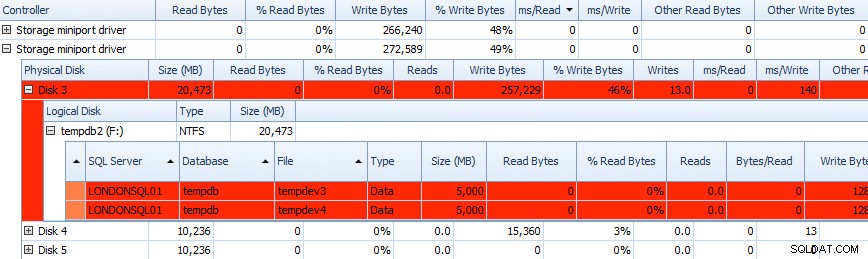 Teilraster von Performance Advisor-Festplattenaktivitätsdaten
Teilraster von Performance Advisor-Festplattenaktivitätsdaten
Sie können diese Informationen auch rückwirkend einsehen; Wenn sich jemand gestern Nachmittag oder letzten Dienstag über einen wahrgenommenen Festplattenengpass beschwert, können Sie einfach mit der Datumsauswahl in der Symbolleiste zurückgehen und den durchschnittlichen Durchsatz und die Latenz für jeden Bereich anzeigen. Weitere Informationen zum Festplattenaktivitätsmodul finden Sie im Benutzerhandbuch.
Performance Advisor verfügt auch über viele integrierte Berichte in den Kategorien Leistung, Blockierung, Top-SQL, Festplatten-/Dateispeicherplatz und Deadlocks. Das folgende Bild zeigt Ihnen, wie Sie zu den Disk/File Space-Berichten gelangen. Es ist sehr wertvoll, die Berichte nur wenige Mausklicks entfernt zu haben, um sofort eintauchen und sehen zu können, was auf Ihrem Server passiert (oder war).
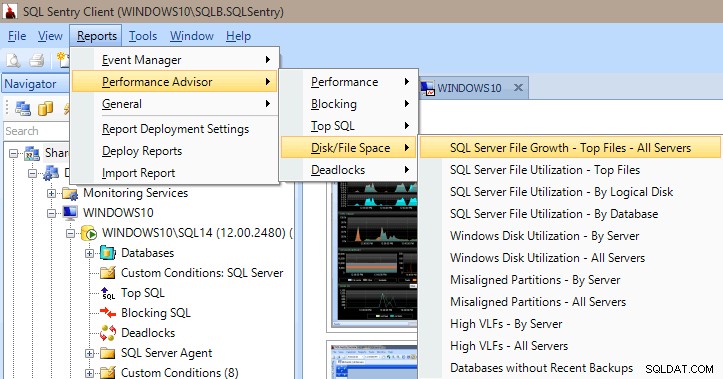 Performance Advisor-Berichte
Performance Advisor-Berichte
Zusammenfassung
Die wichtige Erkenntnis aus diesem Beitrag ist, Ihre Leistungskennzahlen zu kennen. Eine gängige Aussage unter Datenexperten ist, dass die Festplatte unser Engpass Nr. 1 ist. Die Kenntnis der Dateistatistiken Ihres Servers trägt wesentlich dazu bei, die Schwachstellen auf Ihrem Server zu verstehen. In Verbindung mit den Dateistatistiken sind Ihre Wartestatistiken ebenfalls ein großartiger Ort, um nachzuschauen. Viele Menschen, mich eingeschlossen, fangen dort an. Ein Tool wie SQL Sentry Performance Advisor kann Ihnen bei der Fehlerbehebung und Erkennung von Leistungsproblemen erheblich helfen, bevor sie zu problematisch werden. Wenn Sie jedoch kein solches Tool haben, machen Sie sich mit sys.dm_os_wait_stats vertraut und sys.dm_io_virtual_file_stats wird Ihnen gute Dienste leisten, um mit der Optimierung Ihres Servers zu beginnen.



