Datenprofis kommen nicht immer mit optimal gestalteten Datenbanken zurecht. Manchmal sind die Dinge, die dich zum Weinen bringen, Dinge, die wir uns selbst angetan haben, weil sie uns damals wie gute Ideen erschienen. Manchmal sind sie auf Anwendungen von Drittanbietern zurückzuführen. Manchmal sind sie dir einfach voraus.
Die eine, an die ich in diesem Beitrag denke, ist, wenn Ihre datetime- (oder datetime2- oder noch besser datetimeoffset-)Spalte tatsächlich aus zwei Spalten besteht – eine für das Datum und eine für die Zeit. (Wenn du wieder eine eigene Spalte für den Ausgleich hast, dann werde ich dich das nächste Mal umarmen, wenn ich dich sehe, weil du wahrscheinlich mit allerlei Verletzungen fertig werden musstest.)
Ich habe eine Umfrage auf Twitter durchgeführt und festgestellt, dass dies ein sehr reales Problem ist, mit dem sich etwa die Hälfte von Ihnen von Zeit zu Zeit mit Datum und Uhrzeit auseinandersetzen muss.
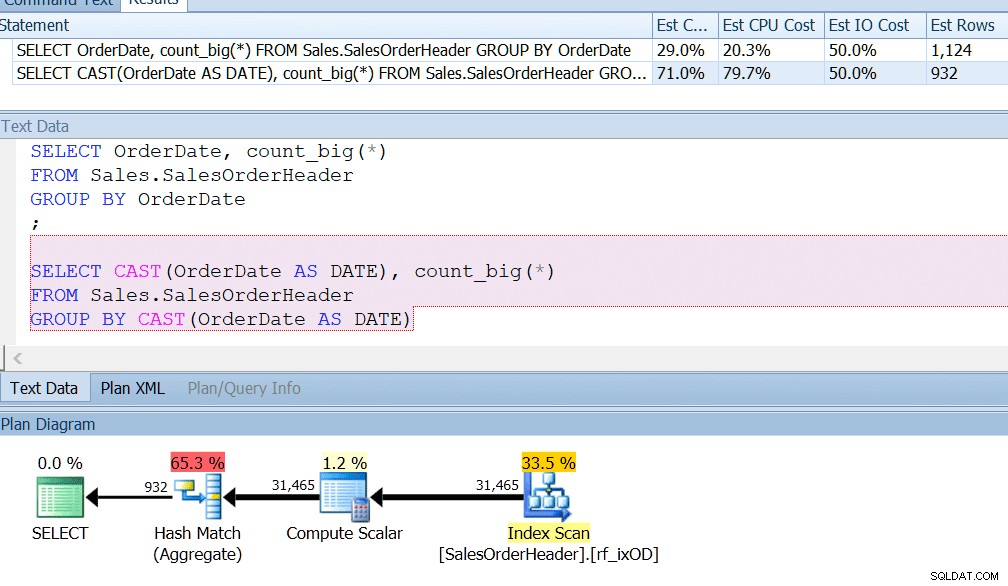
AdventureWorks tut dies fast – wenn Sie in der Sales.SalesOrderHeader-Tabelle nachsehen, sehen Sie eine datetime-Spalte namens OrderDate, die immer genaue Daten enthält. Ich wette, wenn Sie ein Berichtsentwickler bei AdventureWorks sind, haben Sie wahrscheinlich Abfragen geschrieben, die nach der Anzahl der Bestellungen an einem bestimmten Tag suchen, indem Sie GROUP BY OrderDate oder ähnliches verwenden. Selbst wenn Sie wüssten, dass dies eine datetime-Spalte ist und möglicherweise auch eine Nicht-Mitternachtszeit gespeichert werden könnte, würden Sie immer noch GROUP BY OrderDate sagen, nur um einen Index richtig zu verwenden. GROUP BY CAST (OrderDate AS DATE) reicht einfach nicht aus.
Ich habe einen Index für OrderDate, so wie Sie es tun würden, wenn Sie diese Spalte regelmäßig abfragen würden, und ich sehe, dass die Gruppierung nach CAST (OrderDate AS DATE) aus CPU-Sicht etwa viermal schlechter ist.
Ich verstehe also, warum Sie Ihre Spalte gerne so abfragen würden, als ob es sich um ein Datum handelt, einfach weil Sie wissen, dass Sie eine Welt voller Schmerzen haben werden, wenn sich die Verwendung dieser Spalte ändert. Vielleicht lösen Sie dies, indem Sie eine Einschränkung auf dem Tisch haben. Vielleicht hast du einfach den Kopf in den Sand gesteckt.
Und wenn jemand daherkommt und sagt „Weißt du, wir sollten auch die Zeit speichern, zu der Bestellungen ausgeführt werden“, nun, dann denkst du an all den Code, der davon ausgeht, dass OrderDate einfach ein Datum ist, und stellst dir vor, dass eine separate Spalte namens OrderTime (Datentyp Zeit, bitte) wird die sinnvollste Option sein. Ich verstehe. Es ist nicht ideal, aber es funktioniert, ohne zu viel Material zu beschädigen.
An dieser Stelle empfehle ich Ihnen, auch OrderDateTime zu erstellen, was eine berechnete Spalte wäre, die die beiden verbindet (was Sie tun sollten, indem Sie die Anzahl der Tage seit Tag 0 zu CAST (OrderDate als datetime2) hinzufügen, anstatt zu versuchen, die Zeit hinzuzufügen Datum, das im Allgemeinen viel chaotischer ist). Und dann OrderDateTime indizieren, denn das wäre sinnvoll.
Aber ziemlich oft finden Sie sich mit Datum und Uhrzeit als separate Spalten wieder, ohne dass Sie im Grunde nichts dagegen tun können. Sie können keine berechnete Spalte hinzufügen, da es sich um eine Drittanbieteranwendung handelt und Sie nicht wissen, was möglicherweise kaputt geht. Sind Sie sicher, dass sie niemals SELECT * machen? Ich hoffe, dass sie uns eines Tages erlauben, Spalten hinzuzufügen und sie zu verstecken, aber vorerst riskieren Sie sicherlich, Dinge zu beschädigen.
Und, wissen Sie, sogar msdb macht das. Sie sind beide ganze Zahlen. Und das liegt an der Abwärtskompatibilität, nehme ich an. Aber ich bezweifle, dass Sie erwägen, einer Tabelle in msdb eine berechnete Spalte hinzuzufügen.
Wie fragen wir das also ab? Angenommen, wir möchten die Einträge finden, die sich innerhalb eines bestimmten Datums-Zeit-Bereichs befanden?
Lassen Sie uns etwas experimentieren.
Lassen Sie uns zuerst eine Tabelle mit 3 Millionen Zeilen erstellen und die Spalten indizieren, die uns wichtig sind.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Ich hätte daraus einen geclusterten Index machen können, aber ich denke, dass ein nicht geclusterter Index eher typisch für Ihre Umgebung ist.)
Unsere Daten sehen so aus, und ich möchte Zeilen zwischen dem 2. August 2011 um 8:30 Uhr und dem 5. August 2011 um 21:30 Uhr finden.
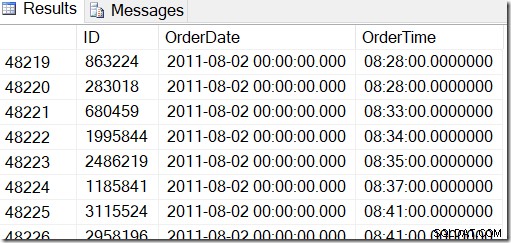
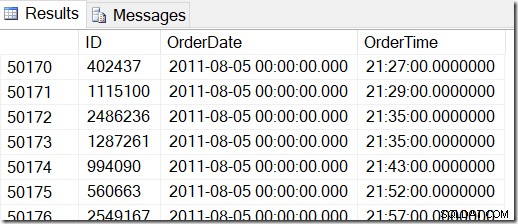
Wenn ich die Daten durchsehe, kann ich sehen, dass ich alle Zeilen zwischen 48221 und 50171 haben möchte. Das sind 50171-48221+1=1951 Zeilen (die +1 ist, weil es sich um einen inklusiven Bereich handelt). Dies hilft mir, sicher zu sein, dass meine Ergebnisse korrekt sind. Sie hätten wahrscheinlich ähnliche Werte auf Ihrem Computer, aber nicht exakt, da ich beim Generieren meiner Tabelle Zufallswerte verwendet habe.
Ich weiß, dass ich so etwas nicht einfach machen kann:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
… weil dies nicht etwas beinhalten würde, das am 4. über Nacht passiert ist. Das gibt mir 1268 Zeilen – eindeutig nicht richtig.
Eine Möglichkeit besteht darin, die Spalten zu kombinieren:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Dies liefert die richtigen Ergebnisse. Es tut. Es ist nur so, dass dies vollständig nicht sargbar ist und uns einen Scan über alle Zeilen in unserer Tabelle gibt. Bei unseren 3 Millionen Zeilen kann es Sekunden dauern, dies auszuführen.
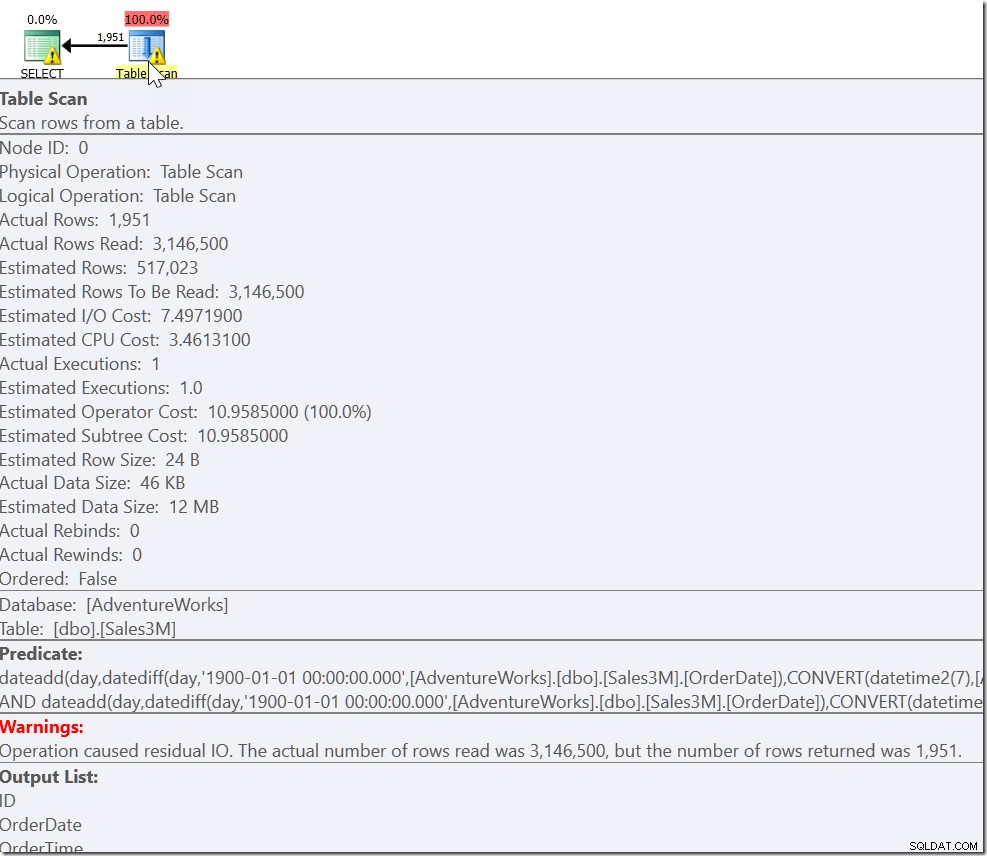
Unser Problem ist, dass wir einen gewöhnlichen Fall und zwei Spezialfälle haben. Wir wissen, dass wir jede Zeile wollen, die OrderDate> „20110802“ UND OrderDate <„20110805“ erfüllt. Aber wir brauchen auch jede Zeile, die am oder nach 8:30 am 20110802 und am oder vor 21:30 am 20110805 ist. Und das führt uns zu:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
OR ist schrecklich, ich weiß. Es kann auch zu Scans führen, wenn auch nicht unbedingt. Hier sehe ich drei Index Seeks, die verkettet und dann auf Eindeutigkeit geprüft werden. Der Abfrageoptimierer erkennt offensichtlich, dass er dieselbe Zeile nicht zweimal zurückgeben sollte, erkennt jedoch nicht, dass sich die drei Bedingungen gegenseitig ausschließen. Und tatsächlich, wenn Sie dies innerhalb eines einzigen Tages auf einer Range tun würden, würden Sie die falschen Ergebnisse erhalten.
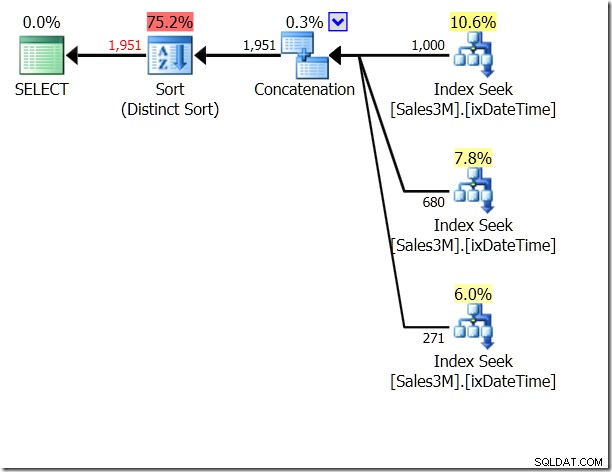
Wir könnten dafür UNION ALL verwenden, was bedeuten würde, dass es dem QO egal wäre, ob sich die Bedingungen gegenseitig ausschließen. Das gibt uns drei Seeks, die verkettet sind – das ist ziemlich gut.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Aber es sind immer noch drei Suchen. Statistics IO sagt mir, dass es 20 Lesevorgänge auf meinem Computer sind.

Wenn ich jetzt an Sargability denke, denke ich nicht nur daran, Indexspalten nicht in Ausdrücke einzufügen, ich denke auch darüber nach, was dazu beitragen könnte, dass etwas scheint tragbar.
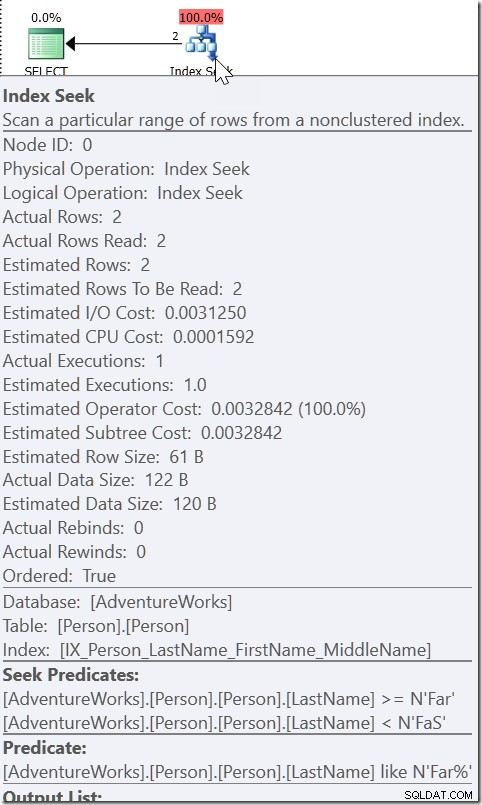
Nehmen Sie zum Beispiel WHERE LastName LIKE 'Far%'. Wenn ich mir den Plan dafür ansehe, sehe ich ein Seek, wobei ein Seek-Prädikat nach einem beliebigen Namen von Far bis (aber nicht einschließlich) FaS sucht. Und dann gibt es noch ein Restprädikat, das die LIKE-Bedingung überprüft. Dies liegt nicht daran, dass die QO der Ansicht ist, dass LIKE Sargable ist. Wenn dies der Fall wäre, wäre es in der Lage, LIKE im Suchprädikat zu verwenden. Weil es weiß, dass alles, was von dieser LIKE-Bedingung erfüllt wird, innerhalb dieses Bereichs liegen muss.
Nehmen Sie WHERE CAST(OrderDate AS DATE) ='20110805'
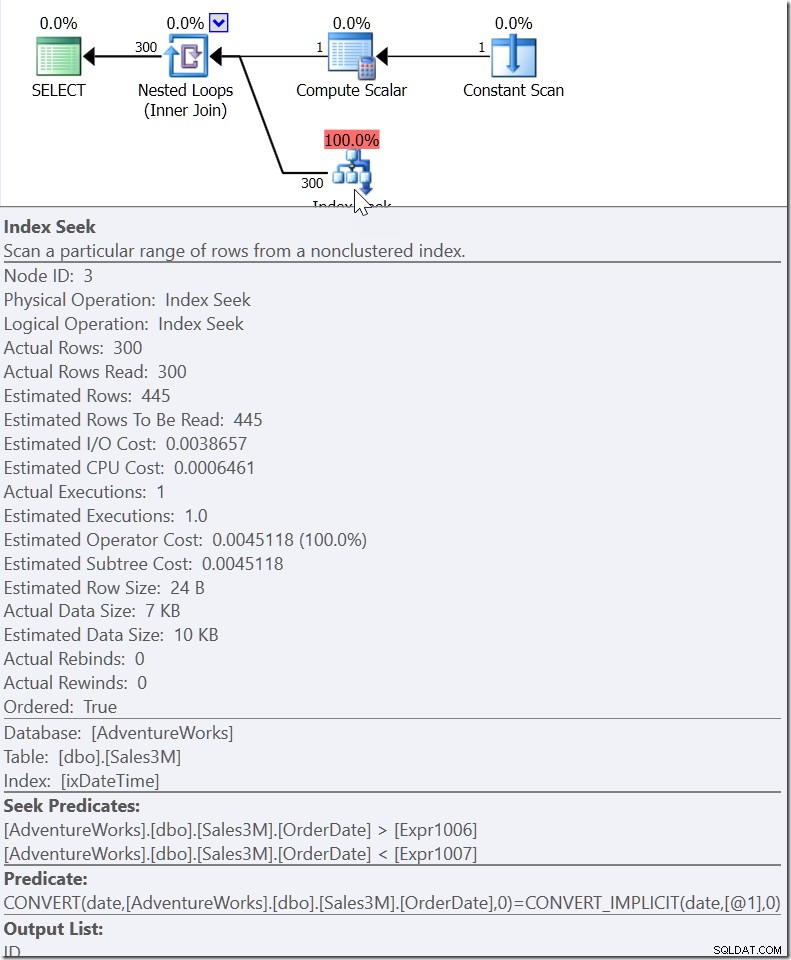
Hier sehen wir ein Suchprädikat, das nach OrderDate-Werten zwischen zwei Werten sucht, die an anderer Stelle im Plan ausgearbeitet wurden, aber einen Bereich erstellt, in dem die richtigen Werte vorhanden sein müssen. Das ist nicht>=20110805 00:00 und <20110806 00:00 (was ich gemacht hätte), es ist etwas anderes. Der Wert für den Beginn dieses Bereichs muss kleiner als 20110805 00:00 sein, da es> und nicht>=ist. Alles, was wir wirklich sagen können, ist, dass jemand bei Microsoft, als er implementierte, wie das QO auf diese Art von Prädikat reagieren sollte, ihm genügend Informationen gegeben hat, um auf das zu kommen, was ich ein „Hilfsprädikat“ nenne.
Nun, ich würde Microsoft lieben, mehr Funktionen sargable zu machen, aber diese spezielle Anfrage wurde geschlossen, lange bevor sie Connect zurückgezogen haben.
Aber vielleicht meine ich damit, dass sie mehr Hilfsprädikate machen.
Das Problem mit Hilfsprädikaten besteht darin, dass sie mit ziemlicher Sicherheit mehr Zeilen lesen, als Sie möchten. Aber es ist immer noch viel besser, als den gesamten Index durchzusehen.
Ich weiß, dass alle Zeilen, die ich zurückgeben möchte, OrderDate zwischen 20110802 und 20110805 haben. Es ist nur so, dass es einige gibt, die ich nicht möchte.
Ich könnte sie einfach entfernen, und das wäre gültig:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
Aber ich habe das Gefühl, dass dies eine Lösung ist, die einige Denkanstrengungen erfordert, um darauf zu kommen. Weniger Aufwand auf Seiten des Entwicklers besteht darin, einfach ein Hilfsprädikat für unsere korrekte, aber langsame Version bereitzustellen.
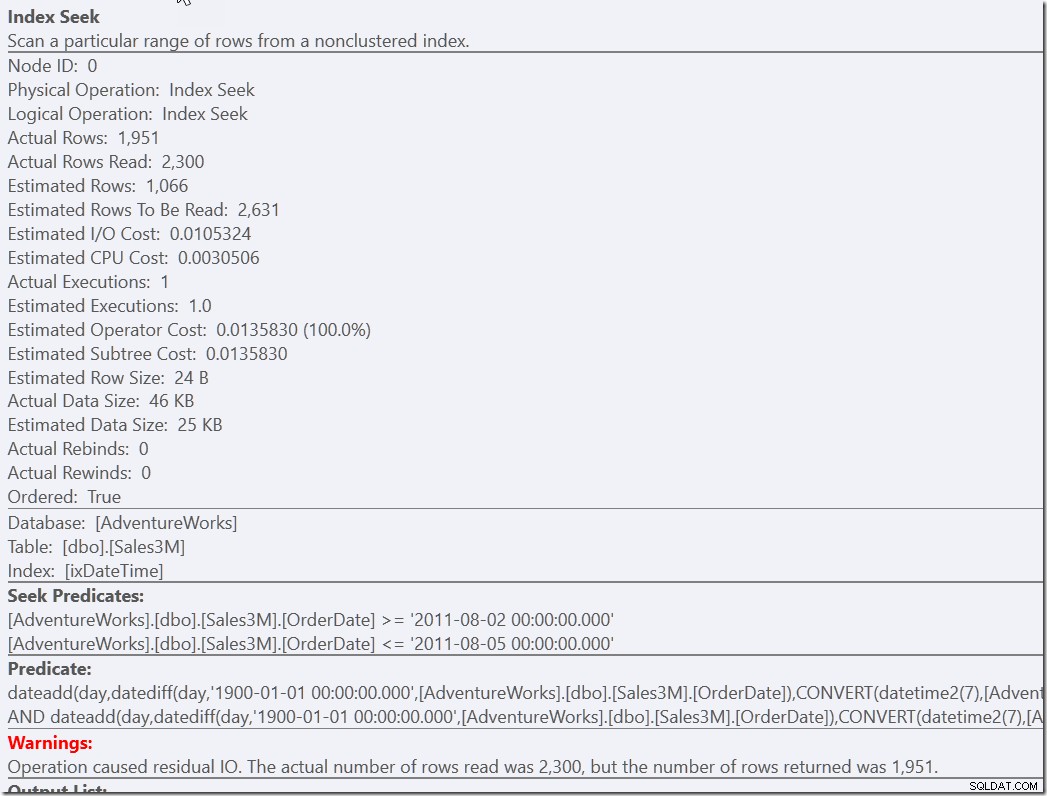
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Diese beiden Abfragen finden die 2300 Zeilen, die sich an den richtigen Tagen befinden, und müssen dann alle diese Zeilen mit den anderen Prädikaten vergleichen. Einer muss die beiden NOT-Bedingungen überprüfen, der andere muss Typkonvertierung und Mathematik durchführen. Aber beide sind viel schneller als das, was wir zuvor hatten, und führen eine einzelne Suche (13 Lesevorgänge) durch. Sicher, ich bekomme Warnungen über einen ineffizienten RangeScan, aber das ist meine Präferenz gegenüber drei effizienten.
In gewisser Weise besteht das größte Problem bei diesem letzten Beispiel darin, dass eine wohlmeinende Person sehen würde, dass das Hilfsprädikat überflüssig ist, und es möglicherweise löschen würde. Dies ist bei allen Hilfsprädikaten der Fall. Also schreib einen Kommentar.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Wenn Sie etwas haben, das nicht in ein nettes sargable Prädikat passt, arbeiten Sie eines aus und finden Sie dann heraus, was Sie davon ausschließen müssen. Vielleicht fällt dir einfach eine schönere Lösung ein.
@rob_farley