Ich habe in letzter Zeit viele Gespräche über Arten von Arbeitslasten geführt – insbesondere darüber, ob eine Arbeitslast parametrisiert, ad hoc oder eine Mischung ist. Dies ist eines der Dinge, die wir uns während eines Integritätsaudits ansehen, und Kimberly hat eine großartige Abfrage aus ihrem Plan-Cache und die Optimierung für Ad-hoc-Arbeitslasten, die Teil unseres Toolkits sind. Ich habe die folgende Abfrage kopiert, und wenn Sie sie noch nie in einer Ihrer Produktionsumgebungen ausgeführt haben, finden Sie auf jeden Fall etwas Zeit dafür.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Wenn ich diese Abfrage in einer Produktionsumgebung ausführe, erhalten wir möglicherweise eine Ausgabe wie die folgende:
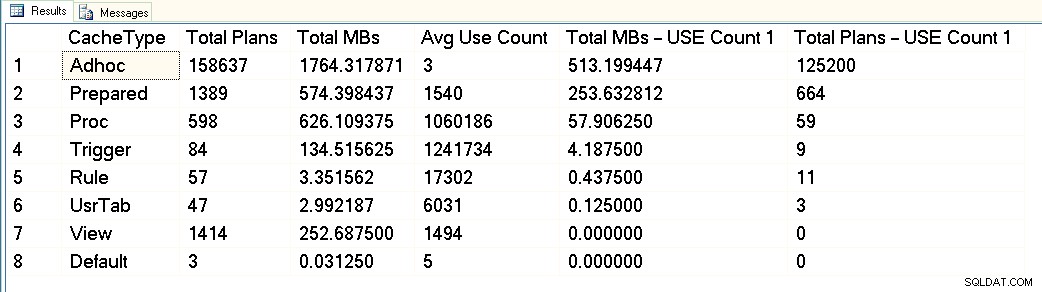
Aus diesem Screenshot können Sie sehen, dass wir insgesamt etwa 3 GB für den Plan-Cache reserviert haben, und davon sind 1,7 GB für die Pläne von über 158.000 Ad-hoc-Abfragen bestimmt. Von diesen 1,7 GB werden ungefähr 500 MB für 125.000 Pläne verwendet, die ONE ausführen nur Zeit. Etwa 1 GB des Plan-Cache ist für vorbereitete Pläne und Verfahrenspläne vorgesehen, die nur etwa 300 MB Speicherplatz beanspruchen. Beachten Sie jedoch die durchschnittliche Anzahl der Benutzer – weit über 1 Million für Verfahren. Wenn ich mir diese Ausgabe ansehe, würde ich diese Workload als gemischt kategorisieren – einige parametrisierte Abfragen, einige Ad-hoc-Anfragen.
In Kimberlys Blog-Beitrag werden Optionen zum Verwalten eines Plan-Cache diskutiert, der mit vielen Ad-hoc-Abfragen gefüllt ist. Plan Cache Bloat ist nur ein Problem, mit dem Sie sich auseinandersetzen müssen, wenn Sie eine Ad-hoc-Workload haben, und in diesem Beitrag möchte ich die Auswirkungen untersuchen, die es aufgrund all der erforderlichen Kompilierungen auf die CPU haben kann. Wenn eine Abfrage in SQL Server ausgeführt wird, durchläuft sie die Kompilierung und Optimierung, und mit diesem Prozess ist ein Overhead verbunden, der sich häufig in CPU-Kosten niederschlägt. Sobald sich ein Abfrageplan im Cache befindet, kann er wiederverwendet werden. Parametrisierte Abfragen können dazu führen, dass ein Plan wiederverwendet wird, der sich bereits im Cache befindet, da der Abfragetext genau derselbe ist. Wenn eine Ad-hoc-Abfrage ausgeführt wird, verwendet sie den Plan im Cache nur dann wieder, wenn er exakt ist gleicher Text und Eingabewert(e) .
Einrichtung
Für unsere Tests generieren wir eine zufällige Zeichenfolge in TSQL und verketten sie mit einer Abfrage, sodass jede Ausführung einen anderen Literalwert hat. Ich habe dies in eine gespeicherte Prozedur eingeschlossen, die die Abfrage mithilfe von Dynamic String Execution (EXEC @QueryString) aufruft, sodass sie sich wie eine Ad-hoc-Anweisung verhält. Der Aufruf aus einer gespeicherten Prozedur heraus bedeutet, dass wir sie eine bekannte Anzahl von Malen ausführen können.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
GO Wenn wir nach der Ausführung den Plan-Cache überprüfen, können wir sehen, dass wir 10 eindeutige Einträge haben, jeder mit einer Ausführungszahl von 1 (vergrößern Sie das Bild bei Bedarf, um die eindeutigen Werte für das Prädikat zu sehen):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Jetzt erstellen wir eine nahezu identische gespeicherte Prozedur, die dieselbe Abfrage ausführt, jedoch parametrisiert:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
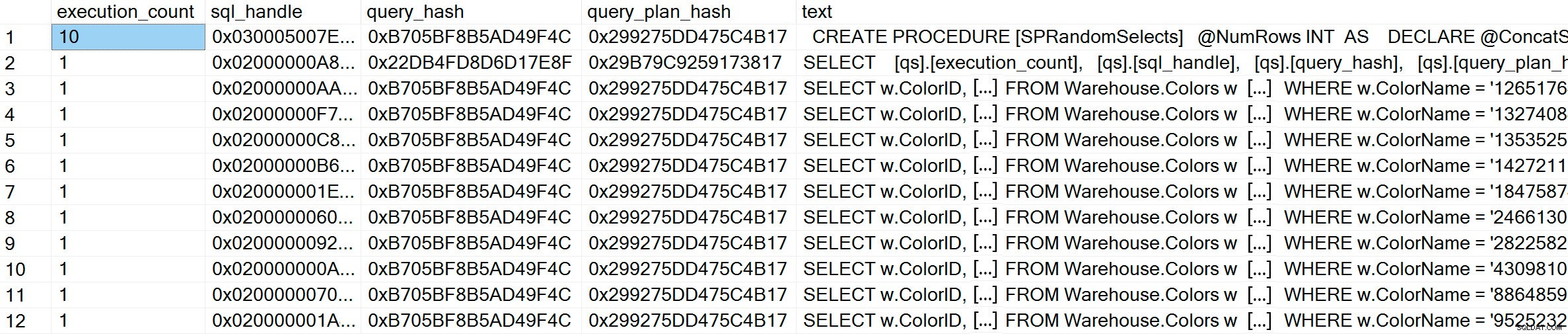
GO Im Plan-Cache sehen wir zusätzlich zu den 10 Ad-hoc-Abfragen einen Eintrag für die parametrisierte Abfrage, die 10 Mal ausgeführt wurde. Da die Eingabe parametrisiert ist, ist der Abfragetext genau gleich, selbst wenn völlig unterschiedliche Zeichenfolgen an den Parameter übergeben werden:
Testen
Nachdem wir nun verstanden haben, was im Plan-Cache passiert, lassen Sie uns mehr Last erzeugen. Wir verwenden eine Befehlszeilendatei, die dieselbe .sql-Datei in 10 verschiedenen Threads aufruft, wobei jede Datei die gespeicherte Prozedur 10.000 Mal aufruft. Wir löschen den Plan-Cache, bevor wir beginnen, und erfassen die Gesamt-CPU in % und die SQL-Kompilierungen/s mit PerfMon, während die Skripts ausgeführt werden.
Inhalt der Adhoc.sql-Datei:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Inhalte der parametrisierten.sql-Datei:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Beispielbefehlsdatei (in Notepad angezeigt), die die .sql-Datei aufruft:
Beispielbefehlsdatei (in Notepad angezeigt), die 10 Threads erstellt, von denen jeder die Datei Run_Adhoc.cmd aufruft:
Nachdem wir jeden Abfragesatz insgesamt 100.000 Mal ausgeführt haben, sehen wir im Plan-Cache Folgendes:

Es gibt mehr als 10.000 Ad-hoc-Pläne im Plan-Cache. Sie fragen sich vielleicht, warum es keinen Plan für alle 100.000 ausgeführten Ad-hoc-Abfragen gibt, und es hat damit zu tun, wie der Plan-Cache funktioniert (seine Größe basiert auf dem verfügbaren Speicher, wenn nicht verwendete Pläne veraltet sind usw.). Entscheidend ist, dass so Es gibt viele Ad-hoc-Pläne, verglichen mit dem, was wir für den Rest der Cache-Typen sehen.
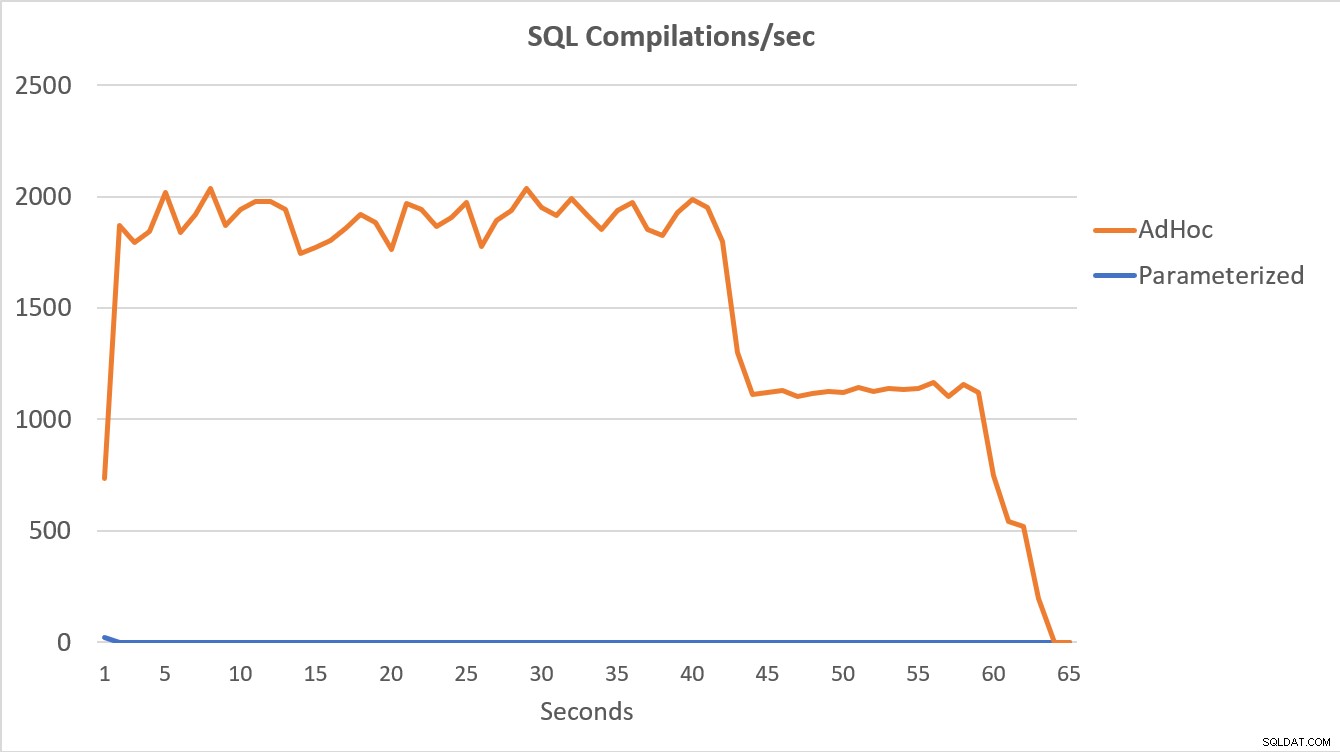
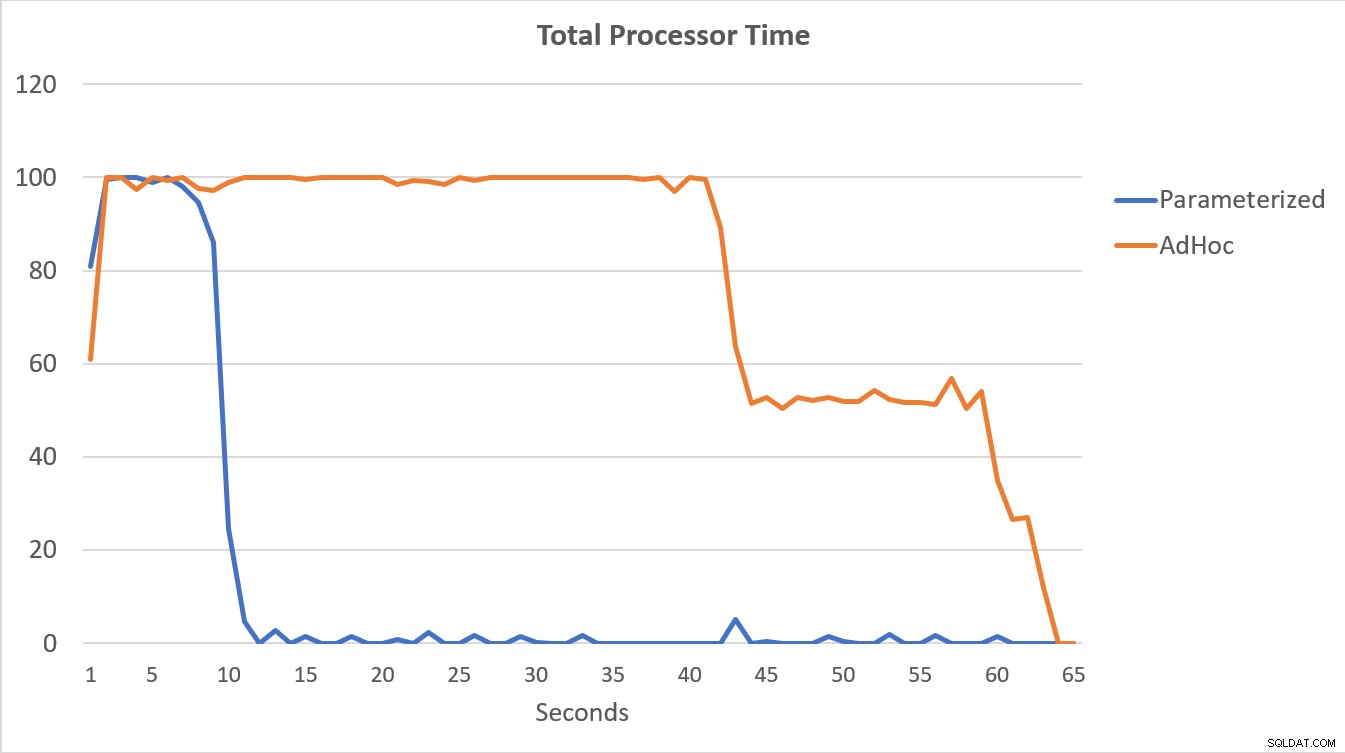
Die unten grafisch dargestellten PerfMon-Daten sind am aussagekräftigsten. Die Ausführung der 100.000 parametrisierten Abfragen wurde in weniger als 15 Sekunden abgeschlossen, und am Anfang gab es eine winzige Spitze bei Compilations/sec, die auf dem Diagramm kaum wahrnehmbar ist. Die gleiche Anzahl von Ad-hoc-Ausführungen dauerte etwas mehr als 60 Sekunden, wobei die Kompilierungen/Sek. einen Spitzenwert von fast 2.000 erreichten, bevor sie um die 45-Sekunden-Marke näher auf 1.000 abfielen, wobei die CPU die meiste Zeit nahe oder bei 100 % lag.
Zusammenfassung
Unser Test war extrem einfach, da wir nur Variationen für eine eingereicht haben Ad-hoc-Abfrage, wohingegen wir in einer Produktionsumgebung Hunderte oder Tausende verschiedener Variationen für Hunderte oder Tausende haben könnten verschiedener Adhoc-Abfragen. Die Leistungsauswirkung dieser Ad-hoc-Abfragen ist nicht nur das Aufblähen des Plan-Cache, obwohl ein Blick auf den Plan-Cache ein guter Ausgangspunkt ist, wenn Sie mit der Art Ihrer Workload nicht vertraut sind. Ein hohes Volumen an Ad-hoc-Abfragen kann Kompilierungen und damit die CPU antreiben, was manchmal durch Hinzufügen weiterer Hardware maskiert werden kann, aber es kann durchaus einen Punkt geben, an dem die CPU zu einem Engpass wird. Wenn Sie der Meinung sind, dass dies ein Problem oder potenzielles Problem in Ihrer Umgebung sein könnte, suchen Sie nach den Ad-hoc-Abfragen, die am häufigsten ausgeführt werden, und prüfen Sie, welche Optionen Sie haben, um sie zu parametrisieren. Verstehen Sie mich nicht falsch – es gibt potenzielle Probleme mit parametrisierten Abfragen (z. B. Planstabilität aufgrund von Datenverzerrung), und das ist ein weiteres Problem, das Sie möglicherweise lösen müssen. Unabhängig von Ihrem Arbeitspensum ist es wichtig zu verstehen, dass es selten eine „einstellen und vergessen“-Methode für Codierung, Konfiguration, Wartung usw. gibt. SQL Server-Lösungen sind lebendige, atmende Einheiten, die sich ständig ändern und kontinuierlich gepflegt und versorgt werden zuverlässig durchführen. Eine der Aufgaben eines DBA besteht darin, bei diesen Änderungen auf dem Laufenden zu bleiben und die Leistung so gut wie möglich zu verwalten – unabhängig davon, ob es sich um Ad-hoc- oder parametrisierte Leistungsherausforderungen handelt.