Mein Freund Peter Larsson schickte mir eine T-SQL-Herausforderung, bei der es darum ging, Angebot und Nachfrage abzugleichen. Was die Herausforderungen angeht, ist es eine gewaltige. Es ist ein ziemlich häufiges Bedürfnis im wirklichen Leben; Es ist einfach zu beschreiben und mit einer Cursor-basierten Lösung recht einfach mit angemessener Leistung zu lösen. Der knifflige Teil besteht darin, es mit einer effizienten satzbasierten Lösung zu lösen.
Wenn Peter mir ein Rätsel schickt, antworte ich normalerweise mit einem Lösungsvorschlag, und er kommt normalerweise mit einer leistungsfähigeren, brillanteren Lösung. Ich vermute manchmal, dass er mir Rätsel schickt, um sich zu motivieren, eine großartige Lösung zu finden.
Da die Aufgabe ein allgemeines Bedürfnis darstellt und so interessant ist, fragte ich Peter, ob es ihm etwas ausmachen würde, wenn ich sie und seine Lösungen mit den Lesern von sqlperformance.com teile, und er ließ es mir gerne.
Diesen Monat stelle ich die Herausforderung und die klassische Cursor-basierte Lösung vor. In nachfolgenden Artikeln werde ich satzbasierte Lösungen vorstellen – einschließlich derjenigen, an denen Peter und ich gearbeitet haben.
Die Herausforderung
Die Herausforderung besteht darin, eine Tabelle namens Auctions abzufragen, die Sie mit dem folgenden Code erstellen:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Diese Tabelle enthält Bedarfs- und Angebotseinträge. Bedarfseinträge sind mit dem Code D und Angebotseinträge mit S gekennzeichnet. Ihre Aufgabe besteht darin, Angebots- und Bedarfsmengen basierend auf der ID-Ordnung abzugleichen und das Ergebnis in eine temporäre Tabelle zu schreiben. Die Einträge können Kauf- und Verkaufsaufträge für Kryptowährungen wie BTC/USD, Kauf- und Verkaufsaufträge für Aktien wie MSFT/USD oder andere Artikel oder Waren darstellen, bei denen Sie Angebot und Nachfrage abgleichen müssen. Beachten Sie, dass den Auktionseinträgen ein Preisattribut fehlt. Wie bereits erwähnt, sollten Sie die Angebots- und Bedarfsmengen basierend auf der ID-Bestellung abgleichen. Diese Reihenfolge könnte vom Preis (aufsteigend für Angebotseinträge und absteigend für Nachfrageeinträge) oder anderen relevanten Kriterien abgeleitet worden sein. Bei dieser Herausforderung war die Idee, die Dinge einfach zu halten und davon auszugehen, dass die ID bereits die relevante Reihenfolge für den Abgleich darstellt.
Verwenden Sie als Beispiel den folgenden Code, um die Tabelle "Auktionen" mit einem kleinen Satz von Beispieldaten zu füllen:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Sie sollten die Angebots- und Nachfragemengen wie folgt abgleichen:
- Eine Menge von 5,0 wird für Nachfrage 1 und Angebot 1000 abgeglichen, wodurch Nachfrage 1 aufgebraucht wird und 3,0 von Angebot 1000 zurückbleibt
- Eine Menge von 3,0 wird für Nachfrage 2 und Angebot 1000 angepasst, wodurch sowohl Nachfrage 2 als auch Angebot 1000 aufgebraucht werden
- Eine Menge von 6,0 wird für Nachfrage 3 und Angebot 2000 abgeglichen, wodurch 2,0 von Nachfrage 3 übrig bleibt und Angebot 2000 aufgebraucht wird
- Eine Menge von 2,0 wird für Nachfrage 3 und Angebot 3000 angepasst, wodurch sowohl Nachfrage 3 als auch Angebot 3000 aufgebraucht werden
- Eine Menge von 2,0 wird für Nachfrage 5 und Angebot 4000 angepasst, wodurch sowohl Nachfrage 5 als auch Angebot 4000 aufgebraucht werden
- Eine Menge von 4,0 wird für Nachfrage 6 und Angebot 5000 angepasst, wodurch 4,0 von Nachfrage 6 übrig bleibt und Angebot 5000 aufgebraucht wird
- Eine Menge von 3,0 wird mit Nachfrage 6 und Angebot 6000 abgeglichen, wodurch 1,0 von Nachfrage 6 übrig bleibt und Angebot 6000 aufgebraucht wird
- Eine Menge von 1,0 wird mit Nachfrage 6 und Angebot 7000 abgeglichen, wodurch Nachfrage 6 aufgebraucht wird und 1,0 von Angebot 7000 verbleibt
- Eine Menge von 1,0 wird für Nachfrage 7 und Angebot 7000 angepasst, wodurch 3,0 von Nachfrage 7 übrig bleibt und Angebot 7000 aufgebraucht wird; Nachfrage 8 wird nicht mit Angebotseinträgen abgeglichen und verbleibt daher bei der vollen Menge 2,0
Ihre Lösung soll die folgenden Daten in die resultierende temporäre Tabelle schreiben:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Großer Satz von Beispieldaten
Um die Leistung der Lösungen zu testen, benötigen Sie einen größeren Satz von Beispieldaten. Dazu können Sie die Funktion GetNums verwenden, die Sie erstellen, indem Sie den folgenden Code ausführen:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Diese Funktion gibt eine Folge von Ganzzahlen im angeforderten Bereich zurück.
Wenn diese Funktion vorhanden ist, können Sie den folgenden von Peter bereitgestellten Code verwenden, um die Tabelle „Auktionen“ mit Beispieldaten zu füllen und die Eingaben nach Bedarf anzupassen:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Wie Sie sehen, können Sie die Anzahl der Käufer und Verkäufer sowie die Mindest- und Höchstmengen für Käufer und Verkäufer anpassen. Der obige Code gibt 200.000 Käufer und 200.000 Verkäufer an, was zu insgesamt 400.000 Zeilen in der Auktionstabelle führt. Die letzte Abfrage gibt an, wie viele Nachfrage- (D) und Angebotseinträge (S) in die Tabelle geschrieben wurden. Es gibt die folgende Ausgabe für die oben genannten Eingaben zurück:
Code Items ---- ----------- D 200000 S 200000
Ich werde die Leistung verschiedener Lösungen mit dem obigen Code testen und die Anzahl der Käufer und Verkäufer jeweils auf die folgenden Werte festlegen:50.000, 100.000, 150.000 und 200.000. Das bedeutet, dass ich die folgende Gesamtanzahl von Zeilen in der Tabelle erhalte:100.000, 200.000, 300.000 und 400.000. Natürlich können Sie die Eingaben nach Belieben anpassen, um die Leistung Ihrer Lösungen zu testen.
Cursor-basierte Lösung
Peter stellte die Cursor-basierte Lösung bereit. Es ist ziemlich einfach, was einer seiner wichtigen Vorteile ist. Es wird als Benchmark verwendet.
Die Lösung verwendet zwei Cursor:einen für nach ID geordnete Bedarfseinträge und einen für nach ID geordnete Angebotseinträge. Um einen vollständigen Scan und eine Sortierung per Cursor zu vermeiden, erstellen Sie den folgenden Index:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Hier ist der Code der vollständigen Lösung:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Wie Sie sehen, beginnt der Code mit der Erstellung einer temporären Tabelle. Dann deklariert es die beiden Cursor und ruft von jedem eine Zeile ab, wobei es die aktuelle Bedarfsmenge in die Variable @DemandQuantity und die aktuelle Angebotsmenge in @SupplyQuantity schreibt. Anschließend verarbeitet er die Einträge in einer Schleife, solange der letzte Abruf erfolgreich war. Der Code wendet die folgende Logik im Hauptteil der Schleife an:
Wenn die aktuelle Bedarfsmenge kleiner oder gleich der aktuellen Angebotsmenge ist, geht der Code wie folgt vor:
- Schreibt eine Zeile in die temporäre Tabelle mit der aktuellen Paarung, mit der Bedarfsmenge (@DemandQuantity) als abgeglichene Menge
- Subtrahiert die aktuelle Bedarfsmenge von der aktuellen Angebotsmenge (@SupplyQuantity)
- Holt die nächste Zeile vom Nachfrage-Cursor
Andernfalls macht der Code Folgendes:
- Überprüft, ob die aktuelle Liefermenge größer als Null ist, und wenn ja, geht es wie folgt vor:
- Schreibt eine Zeile in die temporäre Tabelle mit der aktuellen Paarung, mit der Liefermenge als gematchte Menge
- Subtrahiert die aktuelle Angebotsmenge von der aktuellen Bedarfsmenge
- Holt die nächste Zeile vom Angebotscursor
Sobald die Schleife beendet ist, gibt es keine weiteren Paare, die übereinstimmen müssen, also bereinigt der Code nur die Cursor-Ressourcen.
Aus Leistungssicht erhalten Sie den typischen Overhead des Abrufens und Schleifens des Cursors. Andererseits führt diese Lösung einen einzigen geordneten Durchgang über die Nachfragedaten und einen einzigen geordneten Durchgang über die Angebotsdaten durch, wobei jeder einen Such- und Bereichsscan in dem zuvor erstellten Index verwendet. Die Pläne für die Cursorabfragen sind in Abbildung 1 dargestellt.

Abbildung 1:Pläne für Cursorabfragen
Da der Plan einen Such- und geordneten Bereichsscan jedes der Teile (Nachfrage und Angebot) durchführt, ohne dass eine Sortierung erforderlich ist, weist er eine lineare Skalierung auf. Dies wurde durch die Leistungszahlen bestätigt, die ich beim Testen erhalten habe, wie in Abbildung 2 dargestellt.
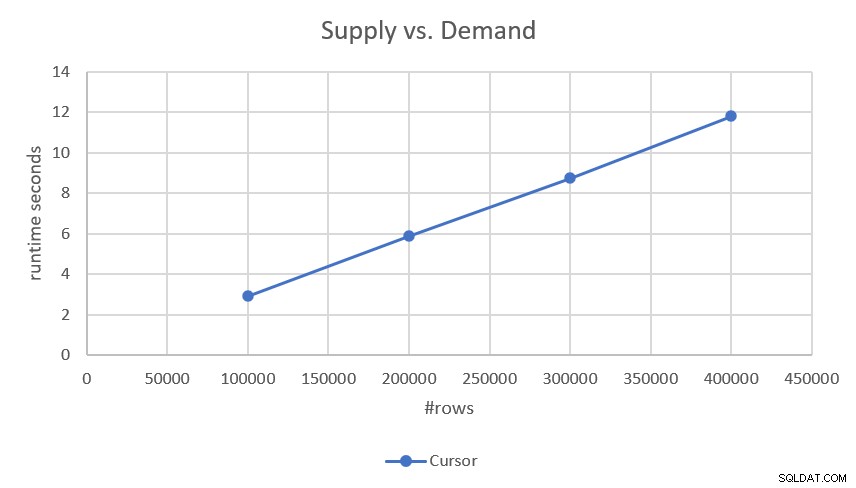
Abbildung 2:Leistung der Cursor-basierten Lösung
Wenn Sie an den genaueren Laufzeiten interessiert sind, hier sind sie:
- 100.000 Zeilen (50.000 Anforderungen und 50.000 Lieferungen):2,93 Sekunden
- 200.000 Zeilen:5,89 Sekunden
- 300.000 Zeilen:8,75 Sekunden
- 400.000 Zeilen:11,81 Sekunden
Da die Lösung über eine lineare Skalierung verfügt, können Sie die Laufzeit mit anderen Skalen leicht vorhersagen. Bei einer Million Zeilen (z. B. 500.000 Anforderungen und 500.000 Lieferungen) sollte die Ausführung beispielsweise etwa 29,5 Sekunden dauern.
Die Herausforderung läuft
Die Cursor-basierte Lösung hat eine lineare Skalierung und ist als solche nicht schlecht. Aber es verursacht den typischen Cursor-Abruf- und Schleifen-Overhead. Natürlich können Sie diesen Overhead reduzieren, indem Sie denselben Algorithmus mit einer CLR-basierten Lösung implementieren. Die Frage ist, können Sie eine gut funktionierende satzbasierte Lösung für diese Aufgabe finden?
Wie bereits erwähnt, werde ich ab nächsten Monat satzbasierte Lösungen untersuchen – sowohl mit schlechter Leistung als auch mit guter Leistung. Wenn Sie der Herausforderung gewachsen sind, versuchen Sie in der Zwischenzeit, ob Sie eigene satzbasierte Lösungen entwickeln können.
Um die Korrektheit Ihrer Lösung zu überprüfen, vergleichen Sie zuerst das Ergebnis mit dem hier gezeigten für den kleinen Satz von Beispieldaten. Sie können die Gültigkeit des Ergebnisses Ihrer Lösung auch mit einem großen Satz von Beispieldaten überprüfen, indem Sie überprüfen, ob die symmetrische Differenz zwischen dem Ergebnis der Cursorlösung und Ihrem leer ist. Angenommen, das Ergebnis des Cursors wird in einer temporären Tabelle mit dem Namen #PairingsCursor und Ihr Ergebnis in einer temporären Tabelle mit dem Namen #MyPairings gespeichert, können Sie dazu den folgenden Code verwenden:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Das Ergebnis sollte leer sein.
Viel Glück!
[ Springe zu den Lösungen:Teil 1 | Teil 2 | Teil 3 ]