Replikation ist die gemeinsame Nutzung von Transaktionsdaten über mehrere Server, um die Konsistenz zwischen redundanten Datenbankknoten sicherzustellen. Ein Master übernimmt Einfügungen oder Aktualisierungen und wendet sie auf seinen Datensatz an, während die Slaves ihre Daten entsprechend den Änderungen am Master-Datensatz ändern. Der Master wird allgemein als Primary bezeichnet und zeichnet die vorgenommenen Änderungen in einem Write Ahead Log (WAL) auf. Slaves hingegen werden als Secondaries bezeichnet und replizieren ihre Daten aus den REDO-Logs - in diesem Fall dem WAL.
Es gibt mindestens 3 Replikationsansätze in PostgreSQL:
Integrierte Replikation oder Streaming-Replikation.
Bei diesem Ansatz werden Daten vom primären Knoten zum sekundären Knoten repliziert. Es bringt jedoch eine Reihe von Rückschlägen mit sich, nämlich:
- Schwierigkeiten bei der Einführung einer neuen Sekundarstufe. Es erfordert, dass Sie den gesamten Zustand replizieren, was ressourcenintensiv sein kann.
- Fehlende integrierte Überwachung und Failover. Im Falle des Versagens des letzteren muss ein Secondary zu einem Primary befördert werden. Häufig kann diese Beförderung zu Dateninkonsistenzen während der Abwesenheit des Primären führen.
Rekonstruktion von WAL
Dieser Ansatz verwendet in gewisser Weise den Streaming-Replikationsansatz, da die Sekundärknoten aus einer Sicherung rekonstruiert werden, die von den Primärknoten erstellt wurde. Die Primärdatenbank führt jeden Tag eine vollständige Datenbanksicherung durch, zusätzlich zu einer inkrementellen Sicherung alle 60 Sekunden. Der Vorteil bei diesem Ansatz besteht darin, dass die Primärseite keiner zusätzlichen Last ausgesetzt wird, bis die Sekundärseiten nahe genug an der Primärseite sind, sodass sie beginnen, das Write-Ahead-Protokoll (WAL) zu streamen, um es einzuholen. Mit diesem Ansatz können Sie Replikate hinzufügen oder entfernen, ohne die Leistung Ihrer PostgreSQL-Datenbank zu beeinträchtigen.
Replikation auf Volume-Ebene für PostgreSQL (Datenträgerspiegelung)
Dies ist ein generischer Ansatz, der nicht nur für PostgreSQL gilt, sondern für alle relationalen Datenbanken. Wir verwenden Distributed Replicated Block Device (DRBD), ein verteiltes repliziertes Speichersystem für Linux. Es soll funktionieren, indem die im Speicher eines Servers gespeicherten Inhalte auf einen anderen gespiegelt werden. Eine einfache Illustration der Struktur ist unten gezeigt.
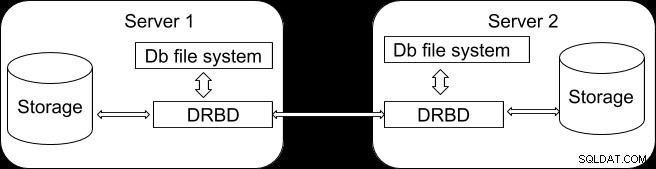
DRBD kann als Abstraktion von dem Plattengerät betrachtet werden, das die PostgreSQL-Datenbank hostet, aber das Betriebssystem wird niemals wissen, dass sich seine Daten auch auf einem anderen Server befinden. Mit diesem Ansatz können Sie nicht nur die Daten, sondern auch das Dateisystem für mehr als einen Server freigeben. Schreibvorgänge auf die DRBD werden daher auf alle Server verteilt, wobei jeder Server Informationen auf eine lokale physische Festplatte (Blockgerät) schreibt. Wenn eine Schreiboperation auf den primären Server angewendet wird, wird sie danach auf dem DRBD aufgezeichnet und dann an die sekundären DRBD-Server verteilt. Wenn andererseits die Sekundärseite die Schreiboperationen über die DRBD empfängt, werden sie dann auf das lokale physische Gerät geschrieben. Im Falle einer Failover-Unterstützung bietet der DRBD eine hohe Datenverfügbarkeit, da die Informationen zwischen einem primären und vielen sekundären Knoten geteilt werden, die synchron auf Blockebene angeordnet sind.
Die DRBD-Konfiguration würde eine zusätzliche Ressource namens Heartbeat erfordern, die wir in einem anderen Artikel besprechen werden, um die Unterstützung für automatisches Failover zu verbessern. Das Paket verwaltet im Wesentlichen die Schnittstelle auf den mehreren Servern und konfiguriert im Falle eines Ausfalls automatisch einen der sekundären Server auf den primären.
Installation und Konfiguration des DRBD
Die bevorzugte Methode bei der Installation von DRBD ist die Verwendung der vorgefertigten binären Installationspakete. Stellen Sie sicher, dass die Kernel-Version der Pakete mit Ihrem aktiven aktuellen Kernel übereinstimmt.
Die Konfigurationsdateien für alle primären oder sekundären Knoten sollten identisch sein. Auch wenn es für Sie notwendig ist, Ihre Kernel-Version zu aktualisieren, stellen Sie sicher, dass das entsprechende Kernel-Modul-DRDB für Ihre neue Kernel-Version verfügbar ist.
DRBD-Setup für Primärknoten
Dies ist der erste Schritt, in dem Sie ein DRBD-Blockgerät und ein Dateisystem erstellen müssen, mit dem Sie Ihre Daten speichern können. Die Konfigurationsdatei finden Sie unter /etc/drbd.conf. Die Datei definiert eine Reihe von Parametern für die DRBD-Konfiguration, darunter:Blockgrößen, Definition der Sicherheitsinformationen der DRBD-Geräte, die Sie erstellen möchten, und Aktualisierungshäufigkeit. Die Konfigurationen können darauf beschränkt werden, global zu sein oder an eine bestimmte Ressource gebunden zu sein. Die beteiligten Schritte sind:
-
Synchronisierungsrate, die die Rate definiert, mit der Geräte nach einem Festplattenaustausch, einem Ausfall oder einer Ersteinrichtung synchron im Hintergrund verbunden werden. Dies kann durch Bearbeiten des Rate-Parameters im Syncer-Block eingestellt werden:
syncer{ rate 15M } -
Authentifizierungseinstellungen, um sicherzustellen, dass nur Hosts mit demselben gemeinsamen Geheimnis der DRBD-Knotengruppe beitreten können. Das Passwort ist ein Hash-Austauschmechanismus, der im DRBD unterstützt wird.
cram-hmac-alg “sha1” shared-secret “hash-password-string” -
Hostinformationen konfigurieren. Die Knoteninformationen wie der Host sind in der drbd.conf-Datei jedes Knotens zu finden. Einige der zu konfigurierenden Parameter sind:
- Adresse:IP-Adresse und Portnummer des Hosts, der das DRBD-Gerät enthält.
- Gerät:Der Pfad des vom DRBD erstellten logischen Blockgeräts.
- Festplatte:Bezieht sich auf das Blockgerät, auf dem die Daten gespeichert sind.
- Meta-Festplatte:Sie speichert die Metadaten des DRBD-Geräts. Seine Größe kann bis zu 128 MB betragen. Sie können festlegen, dass es sich um die interne Festplatte handelt, sodass das DRBD ein physisches Blockgerät verwendet, um diese Informationen in den letzten Abschnitten der Festplatte zu speichern.
Eine einfache Konfiguration für die primäre:
on drbd-one { device /dev/drbd0; disk /dev/sdd1; address 192.168.103.40:8080; meta-disk internal; }Die Konfiguration muss mit den Secondaries mit der IP-Adresse wiederholt werden, die mit ihrem entsprechenden Host übereinstimmt.
on drbd-two { device /dev/drbd0; disk /dev/sdd1; address 192.168.103.41:8080; meta-disk internal; } -
Erstellen der Metadaten für die Geräte mit diesem Befehl:
Dieser Vorgang ist obligatorisch, bevor Sie den primären Knoten starten.$ drbdadm create create-md all - Starten Sie den DRBD mit diesem Befehl:
Dadurch kann der DRBD die vom DRBD definierten Geräte starten, initialisieren und erstellen.$ /etc/init.d/drbd start - Markieren Sie das neue Gerät als primär und initialisieren Sie das Gerät mit diesem Befehl:
Erstellen Sie ein Dateisystem auf dem Blockgerät, um ein vom DRBD erstelltes Standard-Blockgerät nutzbar zu machen.$ drbdadm -- --overwrite-data-of-peer primary all - Machen Sie die Primärdatei einsatzbereit, indem Sie das Dateisystem mounten. Diese Befehle sollten es für Sie vorbereiten:
$ mkdir /mnt/drbd $ mount /dev/drbd0 /mnt/drbd $ echo “DRBD Device” > /mnt/drbd/example_file
DRBD-Setup für den sekundären Knoten
Sie können die gleichen Schritte oben verwenden, außer dass Sie das Dateisystem auf einem sekundären Knoten erstellen, da die Informationen automatisch vom primären Knoten übertragen werden.
-
Kopieren Sie die Datei /etc/drbd.conf vom primären Knoten auf den sekundären Knoten. Diese Datei enthält die erforderlichen Informationen und Konfigurationen.
-
Erstellen Sie auf dem zugrunde liegenden Plattengerät die DRBD-Metadaten mit dem folgenden Befehl:
$ drbdadm create-md all -
Starten Sie den DRBD mit dem Befehl:
DRBD beginnt mit dem Kopieren von Daten vom primären Knoten zum sekundären Knoten, und die Zeit hängt von der Größe der zu übertragenden Daten ab. Wenn Sie die Datei /proc/drbd anzeigen, können Sie den Fortschritt anzeigen.$ /etc/init.d/drbd start$ cat /proc/drbd version: 8.0.0 (api:80/proto:80) SVN Revision: 2947 build by example@sqldat.com, 2018-08-24 16:43:05 0: cs:SyncSource st:Primary/Secondary ds:UpToDate/Inconsistent C r--- ns:252284 nr:0 dw:0 dr:257280 al:0 bm:15 lo:0 pe:7 ua:157 ap:0 [==>.................] sync'ed: 12.3% (1845088/2097152)K finish: 0:06:06 speed: 4,972 (4,580) K/sec resync: used:1/31 hits:15901 misses:16 starving:0 dirty:0 changed:16 act_log: used:0/257 hits:0 misses:0 starving:0 dirty:0 changed:0 -
Überwachen Sie die Synchronisation in bestimmten Abständen mit dem watch-Befehl
$ watch -n 10 ‘cat /proc/drbd‘
DRBD-Installationsverwaltung
Um den DRBD-Gerätestatus zu verfolgen, verwenden wir /proc/drbd.
Mit dem Befehl
können Sie den Zustand aller lokalen Geräte auf primär setzen$ drbdadm primary allMachen Sie ein primäres Gerät zu einem sekundären
$ drbdadm secondary allSo trennen Sie DRBD-Knoten
$ drbdadm disconnect allVerbinden Sie die DRBD-Knoten erneut
$ drbd connect allPostgreSQL für DRBD konfigurieren
Dazu gehört die Auswahl eines Geräts, für das PostgreSQL Daten speichert. Bei einer Neuinstallation können Sie auswählen, ob PostgreSQL vollständig auf dem DRBD-Gerät oder einem Datenverzeichnis installiert werden soll, das sich auf dem neuen Dateisystem befindet und sich auf dem primären Knoten befinden muss. Dies liegt daran, dass der primäre Knoten der einzige ist, der berechtigt ist, ein DRBD-Gerätedateisystem mit Lese-/Schreibzugriff bereitzustellen. Die Postgres-Datendateien werden oft in /var/lib/pgsql archiviert, während die Konfigurationsdateien in /etc/sysconfig/pgsql gespeichert werden.
Einrichten von PostgreSQL zur Verwendung des neuen DRBD-Geräts
-
Wenn PostgreSQL ausgeführt wird, stoppen Sie es mit diesem Befehl:
$ /etc/init.d/postgresql -9.0 -
Aktualisieren Sie das DRBD-Gerät mit den Konfigurationsdateien mit den folgenden Befehlen:
$ mkdir /mnt/drbd/pgsql/sysconfig $ cp /etc/sysconfig/pgsql/* /mnt/drbd/pgsql/sysconfig -
Aktualisieren Sie die DRBD mit PostgreSQL-Datenverzeichnis und Systemdateien mit:
$ cp -pR /var/lib/pgsql /mnt/drbd/pgsql/data -
Erstellen Sie einen symbolischen Link zum neuen Konfigurationsverzeichnis im Dateisystem des DRBD-Geräts von /etc/sysconfig/pgsql mit dem folgenden Befehl:
$ ln -s /mnt/drbd/pgsql/sysconfig /etc/sysconfig/pgsql -
Entfernen Sie das Verzeichnis /var/lib/pgsql, unmounten Sie /mnt/drbd/pgsql und mounten Sie das drbd-Gerät in /var/lib/pgsql.
-
Starten Sie PostgreSQL mit dem Befehl:
$ /etc/init.d/postgresql -9.0 start
Die PostgreSQL-Daten sollten jetzt auf dem Dateisystem vorhanden sein, das auf Ihrem DRBD-Gerät unter dem konfigurierten Gerät ausgeführt wird. Der Inhalt der Datenbanken wird auch auf den sekundären DRBD-Knoten kopiert, aber es kann nicht darauf zugegriffen werden, da das im sekundären Knoten arbeitende DRBD-Gerät möglicherweise nicht vorhanden ist.
Wichtige Merkmale des DRBD-Ansatzes
- Die Abstimmungsparameter sind hochgradig anpassbar.
- Bestehende Bereitstellungen können einfach mit DRBD ohne Datenverlust konfiguriert werden.
- Leseanforderungen sind gleichmäßig verteilt
- Die Shared-Secret-Authentifizierung sichert die Konfiguration und ihre Daten.