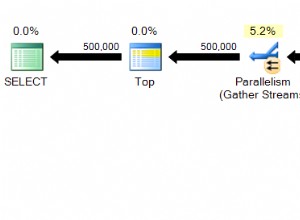
Anstatt ein Flag in report_subscriber zu verwenden selbst, ich denke, Sie wären besser dran mit einer separaten Warteschlange mit ausstehenden Änderungen. Dies hat einige Vorteile:
- Keine Trigger-Rekursion
- Unter der Haube,
UPDATEist nurDELETE+ re-INSERT, also ist das Einfügen in eine Warteschlange tatsächlich billiger als das Umdrehen eines Flags - Möglicherweise um einiges billiger, da Sie nur die eindeutige
report_idin die Warteschlange stellen müssen s, anstatt den gesamtenreport_subscriberzu klonen Datensätze, und Sie können dies in einer temporären Tabelle tun, sodass der Speicher zusammenhängend ist und nichts mit der Festplatte synchronisiert werden muss - Keine Racebedingungen, über die man sich Sorgen machen muss, wenn man die Flags umdreht, da die Warteschlange lokal für die aktuelle Transaktion ist (in Ihrer Implementierung sind die Datensätze betroffen von
UPDATE report_subscribersind nicht unbedingt dieselben Datensätze, die Sie inSELECTausgewählt haben ...)
Initialisieren Sie also die Warteschlangentabelle:
CREATE FUNCTION create_queue_table() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
CREATE TEMP TABLE pending_subscriber_changes(report_id INT UNIQUE) ON COMMIT DROP;
RETURN NULL;
END
$$;
CREATE TRIGGER create_queue_table_if_not_exists
BEFORE INSERT OR UPDATE OF report_id, subscriber_name OR DELETE
ON report_subscriber
FOR EACH STATEMENT
WHEN (to_regclass('pending_subscriber_changes') IS NULL)
EXECUTE PROCEDURE create_queue_table();
... Änderungen in die Warteschlange stellen, sobald sie eintreffen, und alles ignorieren, was bereits in der Warteschlange steht:
CREATE FUNCTION queue_subscriber_change() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
IF TG_OP IN ('DELETE', 'UPDATE') THEN
INSERT INTO pending_subscriber_changes (report_id) VALUES (old.report_id)
ON CONFLICT DO NOTHING;
END IF;
IF TG_OP IN ('INSERT', 'UPDATE') THEN
INSERT INTO pending_subscriber_changes (report_id) VALUES (new.report_id)
ON CONFLICT DO NOTHING;
END IF;
RETURN NULL;
END
$$;
CREATE TRIGGER queue_subscriber_change
AFTER INSERT OR UPDATE OF report_id, subscriber_name OR DELETE
ON report_subscriber
FOR EACH ROW
EXECUTE PROCEDURE queue_subscriber_change();
...und verarbeiten Sie die Warteschlange am Ende der Anweisung:
CREATE FUNCTION process_pending_changes() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
UPDATE report
SET report_subscribers = ARRAY(
SELECT DISTINCT subscriber_name
FROM report_subscriber s
WHERE s.report_id = report.report_id
ORDER BY subscriber_name
)
FROM pending_subscriber_changes c
WHERE report.report_id = c.report_id;
DROP TABLE pending_subscriber_changes;
RETURN NULL;
END
$$;
CREATE TRIGGER process_pending_changes
AFTER INSERT OR UPDATE OF report_id, subscriber_name OR DELETE
ON report_subscriber
FOR EACH STATEMENT
EXECUTE PROCEDURE process_pending_changes();
Dabei gibt es ein kleines Problem:UPDATE bietet keine Garantien für die Update-Reihenfolge. Das bedeutet, wenn diese beiden Anweisungen gleichzeitig ausgeführt werden:
INSERT INTO report_subscriber (report_id, subscriber_name) VALUES (1, 'a'), (2, 'b');
INSERT INTO report_subscriber (report_id, subscriber_name) VALUES (2, 'x'), (1, 'y');
... dann besteht die Möglichkeit eines Deadlocks, wenn sie versuchen, den report zu aktualisieren Aufzeichnungen in entgegengesetzter Reihenfolge. Sie können dies vermeiden, indem Sie eine einheitliche Reihenfolge für alle Updates erzwingen, aber leider gibt es keine Möglichkeit, einen ORDER BY anzuhängen zu einem UPDATE Aussage; Ich denke, Sie müssen auf Cursor zurückgreifen:
CREATE FUNCTION process_pending_changes() RETURNS TRIGGER LANGUAGE plpgsql AS $$
DECLARE
target_report CURSOR FOR
SELECT report_id
FROM report
WHERE report_id IN (TABLE pending_subscriber_changes)
ORDER BY report_id
FOR NO KEY UPDATE;
BEGIN
FOR target_record IN target_report LOOP
UPDATE report
SET report_subscribers = ARRAY(
SELECT DISTINCT subscriber_name
FROM report_subscriber
WHERE report_id = target_record.report_id
ORDER BY subscriber_name
)
WHERE CURRENT OF target_report;
END LOOP;
DROP TABLE pending_subscriber_changes;
RETURN NULL;
END
$$;
Dies kann immer noch zu einem Deadlock führen, wenn der Client versucht, mehrere Anweisungen innerhalb derselben Transaktion auszuführen (da die Aktualisierungsreihenfolge nur innerhalb jeder Anweisung angewendet wird, die Aktualisierungssperren jedoch bis zum Festschreiben gehalten werden). Sie können dies (irgendwie) umgehen, indem Sie process_pending_changes() auslösen nur einmal am Ende der Transaktion (der Nachteil ist, dass Sie innerhalb dieser Transaktion Ihre eigenen Änderungen nicht in den report_subscribers widerspiegeln Array).
Hier ist ein allgemeiner Überblick für einen "On Commit"-Trigger, falls Sie der Meinung sind, dass es sich lohnt, ihn auszufüllen:
CREATE FUNCTION run_on_commit() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
<your code goes here>
RETURN NULL;
END
$$;
CREATE FUNCTION trigger_already_fired() RETURNS BOOLEAN LANGUAGE plpgsql VOLATILE AS $$
DECLARE
already_fired BOOLEAN;
BEGIN
already_fired := NULLIF(current_setting('my_vars.trigger_already_fired', TRUE), '');
IF already_fired IS TRUE THEN
RETURN TRUE;
ELSE
SET LOCAL my_vars.trigger_already_fired = TRUE;
RETURN FALSE;
END IF;
END
$$;
CREATE CONSTRAINT TRIGGER my_trigger
AFTER INSERT OR UPDATE OR DELETE ON my_table
DEFERRABLE INITIALLY DEFERRED
FOR EACH ROW
WHEN (NOT trigger_already_fired())
EXECUTE PROCEDURE run_on_commit();