In diesem Hadoop-Tutorial , werden wir Ihnen eine vollständige Einführung in HDFS Federation geben. In diesem Tutorial besprechen wir die HDFS-Architektur, Einschränkungen der aktuellen Architektur von HDFS.
Anschließend werden wir die HDFS Federation-Architektur zusammen mit ihren Vorteilen im Hadoop-Framework ausführlich behandeln.
Was ist HDFS Federation?
Föderation verbessert ein vorhandenes Hadoop HDFS die Architektur. Frühere HDFS-Architekturen ermöglichen einen einzigen Namespace für den gesamten Cluster. In dieser Architektur verwaltet ein einzelner NameNode den Namespace.
Wenn NameNode ausfällt, ist der gesamte Cluster außer Betrieb. Und der Cluster ist nicht verfügbar, bis der NameNode neu gestartet oder auf einen separaten Computer gebracht wird.
HDFS Federation wurde eingeführt, um diese Einschränkung zu überwinden. Es überwindet dies, indem HDFS Unterstützung für viele NameNode/Namespaces hinzugefügt wird.
Aktuelle HDFS-Architektur
HDFS hat zwei Hauptschichten, die unten angegeben sind:
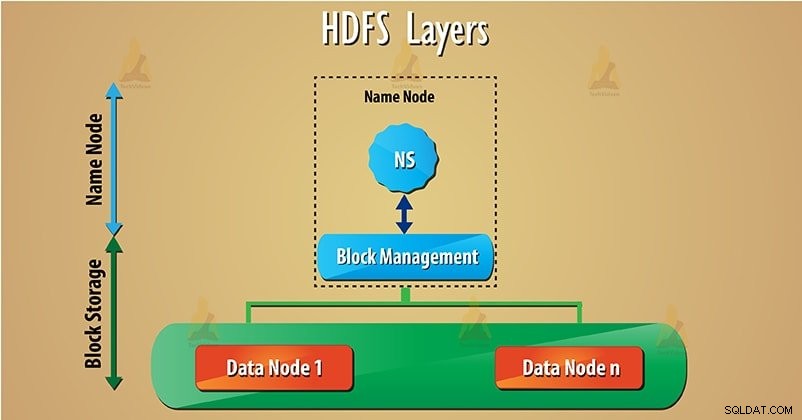
a) Namespace – Diese Ebene verwaltet Dateien, Verzeichnisse und Blöcke . Diese Schicht unterstützt grundlegende Dateisystemoperationen wie das Erstellen und Löschen von Dateien.
b) Speicher blockieren – Es besteht aus zwei Teilen-
- Blockverwaltung – Es unterstützt blockbezogene Operationen wie das Erstellen, Löschen der Blöcke. Es verwaltet Datenknoten im Cluster und kümmert sich um das Replikationsmanagement.
- Physischer Speicher – Dadurch werden die Blöcke im lokalen Dateisystem gespeichert und Zugriff auf Lese- oder Schreibvorgänge bereitgestellt. Folgen Sie diesem Link, um mehr über den Lese- und Schreibvorgang von HDFS-Daten zu erfahren.
Dieses aktuelle HDFS funktioniert gut für kleinere Setups. Für große Organisationen, in denen wir uns um die riesige Datenmenge kümmern müssen, gibt es jedoch einige Einschränkungen. Der Hadoop-Verbund handhabt diese Einschränkungen.
Einschränkung der aktuellen HDFS-Architektur
Einschränkungen der aktuellen HDFS-Architektur sind unten angegeben:
1. Eng gekoppelter Blockspeicher und Namespace
Namespace-Ebene und Speicherschicht sind eng gekoppelt. Dies erschwert die alternative Implementierung von namenode. Und es beschränkt andere Dienste auf die Verwendung von Blockspeicher.
2. Namespace-Skalierbarkeit
Der Namensraum ist nicht skalierbar wie datanode. Die Skalierung im HDFS-Cluster erfolgt horizontal durch Hinzufügen von Datenknoten. Aber wir können einem bestehenden Cluster keinen weiteren Namespace hinzufügen. Wir können den Namensraum auf einem einzelnen Namensknoten vertikal skalieren.
3. Leistung
Die gesamte Leistung von Hadoop hängt vom Durchsatz des Namensknotens ab. Ein Betrieb des aktuellen Dateisystems hängt vom Durchsatz eines einzelnen Namensknotens ab. NameNode unterstützt derzeit 60.000 gleichzeitige Aufgaben.
Demnächst MapReduce wird mehr als 1.00.000 gleichzeitige Aufgaben unterstützen. Und dies wird mehr Namensknoten benötigen.
4. Isolation
Es gibt keine Trennung des Namensraums. Es gibt also keine Isolierung zwischen Mandantenorganisationen, die den Cluster verwenden.
HDFSFöderationsarchitektur
Federation verwendet viele unabhängige Namenode/Namespaces, um den Namensdienst horizontal zu skalieren. In der HDFS-Verbundarchitektur sind unten Datenknoten vorhanden. Und Datenknoten werden von allen Namensknoten als gemeinsamer Speicher für Blöcke verwendet.
Jeder Datenknoten registriert sich bei allen Namensknoten im Cluster. Diese Datenknoten senden periodische Herzschläge, blockieren, melden und verarbeiten Befehle von den Namensknoten.
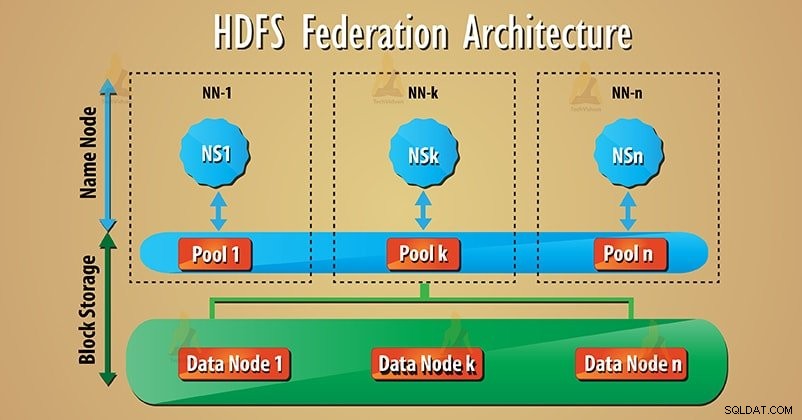
Viele Namenodes (NN1, NN2…, NNn) verwalten jeweils viele Namespaces (NS1, NS2…, NSn). Jeder Namespace hat seinen eigenen Blockpool (NS1 hat Pool 1 usw.). Block aus Pool 1 wird auf Datenknoten 1 gespeichert und so weiter.
1. Pool blockieren
Satz von Blöcken ist Blockpool die zu einem einzigen Namensraum gehört. Es gibt eine Sammlung von Pools in der HDFS-Verbundarchitektur. Und jeder Block wird vom anderen verwaltet.
Dadurch kann ein Namespace eine Block-ID erstellen für neue Blöcke ohne Koordination mit einem anderen Namensraum. Alle Datanodes speichern Datenblöcke, die in allen Blockpools vorhanden sind.
2. Namespace-Volume
Namespace zusammen mit seinem Blockpool ist Namespace-Volume . Viele Namespace-Volumes sind im HDFS-Verbund vorhanden. Daher arbeitet jedes Namespace-Volume unabhängig. Wenn wir Namensknoten oder Namensraum löschen, wird auch der entsprechende Blockpool, der auf den Datenknoten vorhanden ist, gelöscht.
Vorteile des HDFS-Verbunds
HDFS Federation überwindet die Einschränkungen früherer HDFS-Architekturen. Daher bietet es:
- Isolation – In einer Umgebung mit mehreren Benutzern gibt es keine Isolierung in einem einzelnen Namensknoten. In der HDFS-Föderation können verschiedene Kategorien von Anwendungen und Benutzern durch die Verwendung vieler Namenodes auf verschiedene Namespaces isoliert werden.
- Namespace-Skalierbarkeit – In der Föderation skalieren viele Namensknoten im Namensraum des Dateisystems horizontal nach oben.
- Leistung – Wir können den Durchsatz von Lese-/Schreiboperationen verbessern, indem wir mehr Namenodes hinzufügen.
Schlussfolgerung
Abschließend zu HDFS Federation können wir sagen, dass es die Beschränkungen der Single-Node-HDFS-Architektur überwindet. In früheren HDFS-Architekturen für einen gesamten Cluster ist nur ein einziger Namespace zulässig. Während Federation viele unabhängige Namenode/Namespaces verwendet, um den Namensdienst horizontal zu skalieren.
Es trennt auch die Namespace-Ebene und der Speicher Schicht. Bietet daher Isolierung, Skalierbarkeit und einfaches Design.
Wenn Sie Fragen oder Vorschläge zum Verbund in Hadoop HDFS haben, lassen Sie es uns wissen, indem Sie einen Kommentar hinterlassen.



