Auf den Tag genau vor einem Jahr habe ich meine Lösung für die Paginierung in SQL Server gepostet, bei der ein CTE verwendet wurde, um nur die Schlüsselwerte für die fraglichen Zeilen zu finden, und dann vom CTE wieder mit der Quelltabelle verknüpft wurde, um sie abzurufen die anderen Spalten für genau diese "Seite" von Zeilen. Dies erwies sich als am vorteilhaftesten, wenn es einen schmalen Index gab, der die vom Benutzer angeforderte Sortierung unterstützte, oder wenn die Sortierung auf dem Clustering-Schlüssel basierte, aber ohne einen Index zur Unterstützung der erforderlichen Sortierung sogar etwas besser abschnitt.
Seitdem habe ich mich gefragt, ob ColumnStore-Indizes (sowohl geclusterte als auch nicht geclusterte) bei einem dieser Szenarien hilfreich sein könnten. TL;DR :Basierend auf diesem isolierten Experiment ist die Antwort auf den Titel dieses Beitrags ein klares NEIN . Wenn Sie den Testaufbau, den Code, die Ausführungspläne oder Grafiken nicht sehen möchten, können Sie gerne zu meiner Zusammenfassung springen, wobei Sie bedenken sollten, dass meine Analyse auf einem sehr spezifischen Anwendungsfall basiert.
Einrichtung
Auf einer neuen VM mit installiertem SQL Server 2016 CTP 3.2 (13.0.900.73) habe ich ungefähr das gleiche Setup wie zuvor durchlaufen lassen, nur diesmal mit drei Tabellen. Zuerst eine herkömmliche Tabelle mit einem schmalen Clustering-Schlüssel und mehreren unterstützenden Indizes:
CREATE TABLE [dbo].[Customers]( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [ nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([ Kundennummer])); ERSTELLEN SIE NICHT EINGESCHLOSSENEN INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail])WHERE ([Active]=1); -- zur Unterstützung der "PhoneBook"-Sortierung (Reihenfolge nach Last, First)Als nächstes eine Tabelle mit einem gruppierten ColumnStore-Index:
CREATE TABLE [dbo].[Customers_CCI]( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [ nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([ Kundennummer])); ERSTELLEN SIE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];Und schließlich eine Tabelle mit einem nicht geclusterten ColumnStore-Index, der alle Spalten abdeckt:
CREATE TABLE [dbo].[Customers_NCCI]( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [ nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED ([ Kundennummer])); CREATE NONCLLUSTERED COLUMNSTORE INDEX [Customers_NCCI] ON [dbo].[Customers_NCCI]( [CustomerID], [FirstName], [LastName], [E-Mail], [Active], [Created], [Updated]);Beachten Sie, dass ich für beide Tabellen mit ColumnStore-Indizes den Index weggelassen habe, der schnellere Suchvorgänge in der Sortierung "PhoneBook" (Nachname, Vorname) unterstützen würde.
Testdaten
Ich habe dann die erste Tabelle mit 1.000.000 zufälligen Zeilen gefüllt, basierend auf einem Skript, das ich aus früheren Beiträgen wiederverwendet habe:
INSERT dbo.Customers WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln, em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (PARTITION BY em ORDER BY em) FROM ( SELECT TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT (c.name, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID ())),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WO r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn;Dann habe ich diese Tabelle verwendet, um die anderen beiden mit genau denselben Daten zu füllen, und alle Indizes neu erstellt:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active])SELECT CustomerID, FirstName, LastName, EMail, [Active]FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active])SELECT CustomerID, FirstName, LastName, EMail, [Active]FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD;ALTER INDEX ALL ON dbo.Customers_CCI REBUILD;ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;Die Gesamtgröße jeder Tabelle:
| Tabelle | Reserviert | Daten | Index |
|---|---|---|---|
| Kunden | 463.200 KB | 154.344 KB | 308.576 KB |
| Kunden_CCI | 117.280 KB | 30.288 KB | 86.536 KB |
| Kunden_NCCI | 349.480 KB | 154.344 KB | 194.976 KB |
Und die Anzahl der Zeilen / Seiten der relevanten Indizes (der eindeutige Index für E-Mail war mehr für mich da, um mein eigenes Datengenerierungsskript zu babysitten als für alles andere):
| Tabelle | Index | Zeilen | Seiten |
|---|---|---|---|
| Kunden | PK_Kunden | 1.000.000 | 19.377 |
| Kunden | PhoneBook_Customers | 1.000.000 | 17.209 |
| Kunden | Aktive_Kunden | 808.012 | 13.977 |
| Kunden_CCI | PK_CustomersCCI | 1.000.000 | 2.737 |
| Kunden_CCI | Kunden_CCI | 1.000.000 | 3.826 |
| Kunden_NCCI | PK_CustomersNCCI | 1.000.000 | 19.377 |
| Kunden_NCCI | Kunden_NCCI | 1.000.000 | 16.971 |
Verfahren
Um dann zu sehen, ob die ColumnStore-Indizes eingreifen und eines der Szenarien verbessern würden, habe ich die gleichen Abfragen wie zuvor ausgeführt, aber jetzt für alle drei Tabellen. Ich bin zumindest ein bisschen schlauer geworden und habe zwei gespeicherte Prozeduren mit dynamischem SQL erstellt, um die Tabellenquelle und die Sortierreihenfolge zu akzeptieren. (Ich bin mir der SQL-Injektion sehr wohl bewusst; das würde ich in der Produktion nicht tun, wenn diese Zeichenfolgen von einem Endbenutzer stammen würden, also verstehen Sie es bitte nicht als Empfehlung. Ich vertraue mir gerade genug in meine geschlossene Umgebung, dass dies für diese Tests kein Problem darstellt.)
CREATE PROCEDURE dbo.P_Old @PageNumber INT =1, @PageSize INT =100, @Table SYSNAME, @Sort VARCHAR(32)ASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N' SELECT CustomerID, FirstName, LastName, EMail, Active, Created, Updated FROM dbo.' + QUOTENAME(@Table) + N' ORDER BY ' + CASE @Sort WHEN 'Key' THEN N'CustomerID' WHEN 'PhoneBook' THEN N'LastName, FirstName' WHEN 'Unsupported' THEN N'FirstName DESC, EMail' END + N' OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);'; EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;ENDGO CREATE PROCEDURE dbo.P_CTE @PageNumber INT =1, @PageSize INT =100, @Table SYSNAME, @Sort VARCHAR( 32)ASBEGIN NOCOUNT EINSTELLEN; DECLARE @sql NVARCHAR(MAX) =N';WITH pg AS ( SELECT CustomerID FROM dbo.' + QUOTENAME(@Table) + N' ORDER BY ' + CASE @Sort WHEN 'Key' THEN N'CustomerID' WHEN 'PhoneBook' THEN N'Nachname, Vorname' WHEN 'Nicht unterstützt' DANN N'Vorname DESC, EMail' END + N' OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT c.CustomerID, c.FirstName, c.Nachname, c.E-Mail, c.Aktiv, c.Erstellt, c.Aktualisiert von dbo.' + QUOTENAME(@Table) + N' AS c WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID =c.CustomerID) ORDER BY ' + CASE @Sort WHEN 'Key' THEN N'CustomerID' WHEN 'PhoneBook' THEN N' Nachname, Vorname' WHEN 'Nicht unterstützt' THEN N'Vorname DESC, E-Mail' END + N' OPTION (NEU KOMPILIEREN);'; EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;ENDGO
Dann habe ich etwas mehr dynamisches SQL entwickelt, um alle Kombinationen von Aufrufen zu generieren, die ich machen müsste, um sowohl die alten als auch die neuen gespeicherten Prozeduren in allen drei gewünschten Sortierreihenfolgen und an verschiedenen Seitenzahlen aufzurufen (um die Notwendigkeit von eine Seite am Anfang, in der Mitte und am Ende der Sortierreihenfolge). Damit ich PRINT kopieren konnte ausgeben und in den SQL Sentry Plan Explorer einfügen, um Laufzeitmetriken zu erhalten, habe ich diesen Stapel zweimal ausgeführt, einmal mit den procedures CTE mit P_Old , und dann wieder mit P_CTE .
DECLARE @sql NVARCHAR(MAX) =N'';;MIT [Tabellen](Name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI'),sorts(sort) AS( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Nicht unterstützt'),Seiten(Seitenzahl) AS( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999),Prozeduren(Name) AS( SELECT N'P_CTE' -- N'P_Old')SELECT @sql +=N' EXEC dbo.' + p.name + N' @Table =N' + CHAR(39) + t.name + CHAR(39) + N', @Sort =N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber =' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';'FROM Tabellen AS t CROSS JOIN sortiert AS s CROSS JOIN Seiten AS pg CROSS JOIN Prozeduren AS p ORDER BY t.name, s .sort, Seite.Seitenzahl; PRINT @sql;
Dies erzeugte eine Ausgabe wie diese (insgesamt 36 Aufrufe für die alte Methode (P_Old ) und 36 Aufrufe für die neue Methode (P_CTE )):
EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =1; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =500; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =5000; EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Key', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Kunden', @Sort =N'Telefonbuch', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Kunden', @Sort =N'Telefonbuch', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Kunden', @Sort =N'Nicht unterstützt', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Customers', @Sort =N'Unsupported', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Customers_CCI', @Sort =N'Key', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Customers_CCI', @Sort =N'Unsupported', @PageNumber =9999; EXEC dbo.P_CTE @Table =N'Customers_NCCI', @Sort =N'Key', @PageNumber =1; ... EXEC dbo.P_CTE @Table =N'Customers_NCCI', @Sort =N'Unsupported', @PageNumber =9999;
Ich weiß, das ist alles sehr umständlich; Wir kommen bald zur Pointe, versprochen.
Ergebnisse
Ich nahm diese beiden Sätze von 36 Anweisungen und startete zwei neue Sitzungen im Plan Explorer, wobei ich jeden Satz mehrmals ausführte, um sicherzustellen, dass wir Daten aus einem warmen Cache erhielten, und Mittelwerte nahm (ich könnte auch kalten und warmen Cache vergleichen, aber ich denke, es gibt genügend Variablen hier).
Ich kann Ihnen auf Anhieb ein paar einfache Fakten nennen, ohne Ihnen auch nur unterstützende Grafiken oder Pläne zu zeigen:
- In keinem Szenario hat die "alte" Methode die neue CTE-Methode geschlagen Ich habe in meinem vorherigen Beitrag beworben, egal welche Art von Indizes vorhanden waren. Das macht es einfach, die Hälfte der Ergebnisse praktisch zu ignorieren, zumindest in Bezug auf die Dauer (das ist die Metrik, die den Endbenutzern am meisten am Herzen liegt).
- Kein ColumnStore-Index schnitt beim Paging zum Ende des Ergebnisses gut ab – sie erbrachten nur zu Beginn und nur in wenigen Fällen Vorteile.
- Beim Sortieren nach dem Primärschlüssel (geclustert oder nicht), das Vorhandensein von ColumnStore-Indizes hat nicht geholfen – wieder in Bezug auf die Dauer.
Nachdem wir diese Zusammenfassungen aus dem Weg geräumt haben, werfen wir einen Blick auf einige Querschnitte der Dauerdaten. Zuerst die Ergebnisse der Abfrage, sortiert nach Vornamen absteigend, dann E-Mail, ohne Hoffnung, einen vorhandenen Index zum Sortieren zu verwenden. Wie Sie im Diagramm sehen können, war die Leistung uneinheitlich – bei niedrigeren Seitenzahlen schnitt der nicht geclusterte ColumnStore am besten ab; bei höheren Seitenzahlen hat der traditionelle Index immer gewonnen:
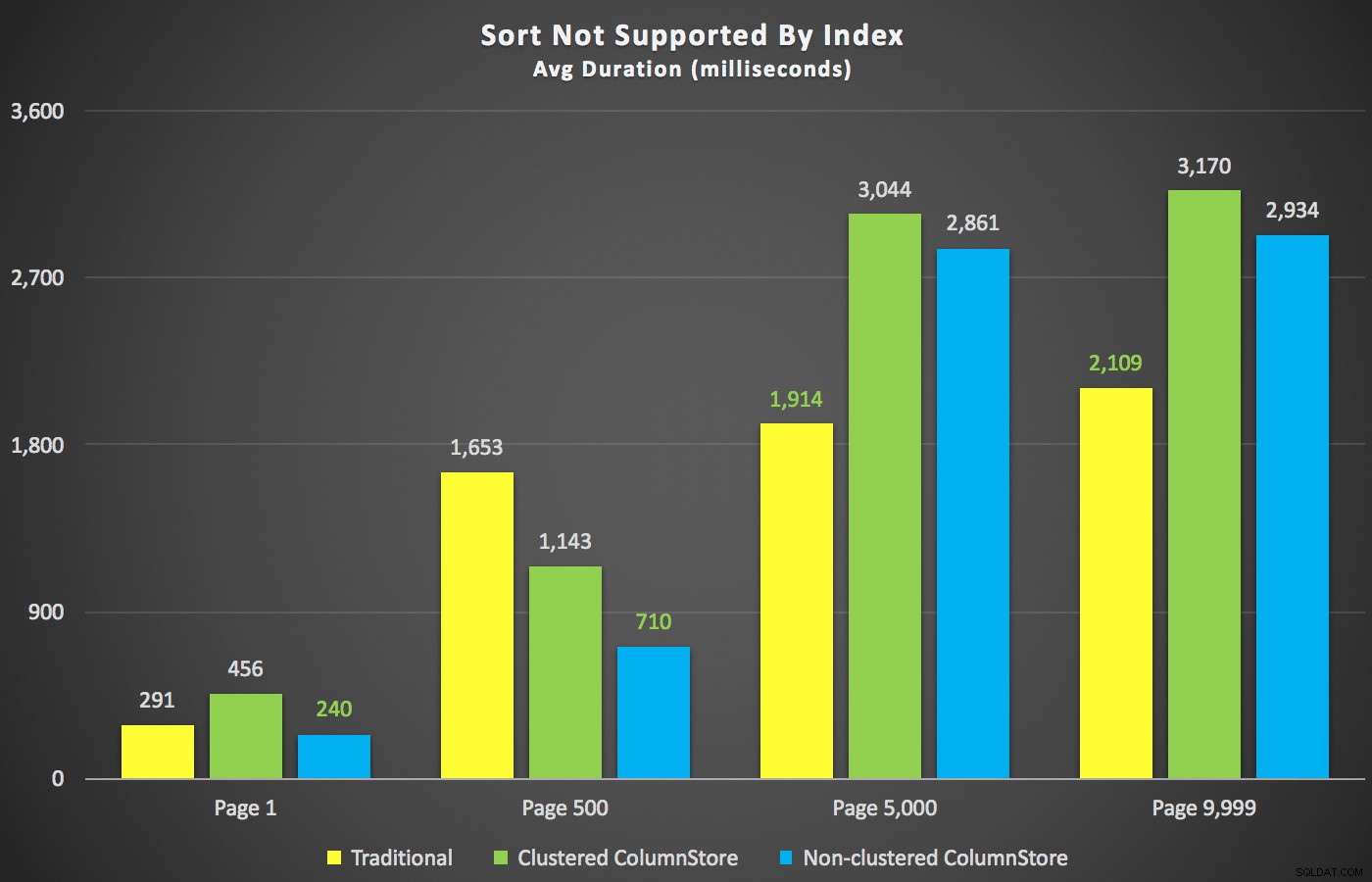 Dauer (Millisekunden) für verschiedene Seitenzahlen und verschiedene Indextypen
Dauer (Millisekunden) für verschiedene Seitenzahlen und verschiedene Indextypen
Und dann die drei Pläne, die die drei verschiedenen Arten von Indizes darstellen (mit von Photoshop hinzugefügten Graustufen, um die Hauptunterschiede zwischen den Plänen hervorzuheben):
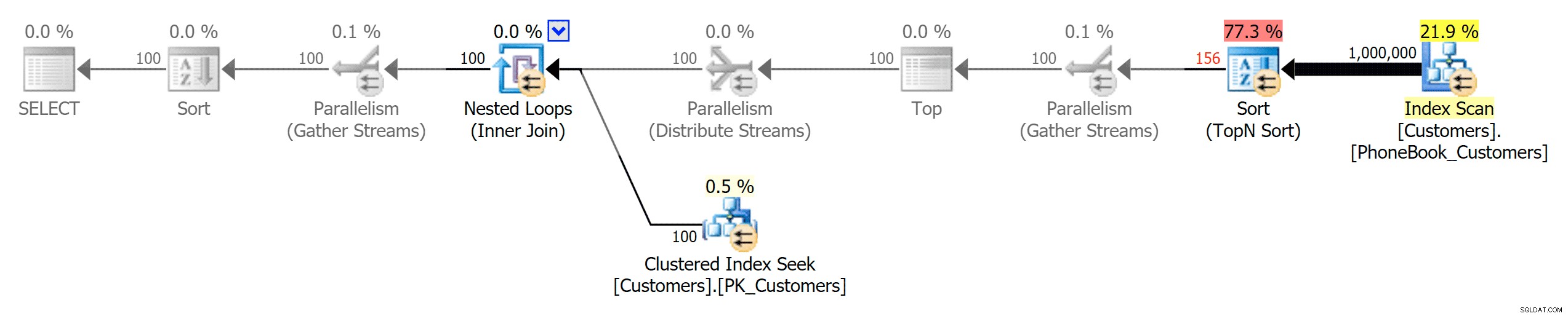 Traditionellen Index planen
Traditionellen Index planen
 Planen Sie einen gruppierten ColumnStore-Index
Planen Sie einen gruppierten ColumnStore-Index
 Planen Sie einen nicht geclusterten ColumnStore-Index
Planen Sie einen nicht geclusterten ColumnStore-Index
Ein Szenario, das mich mehr interessierte, noch bevor ich mit dem Testen begann, war der Ansatz der Telefonbuchsortierung (Nachname, Vorname). In diesem Fall waren die ColumnStore-Indizes tatsächlich ziemlich schädlich für die Leistung des Ergebnisses:
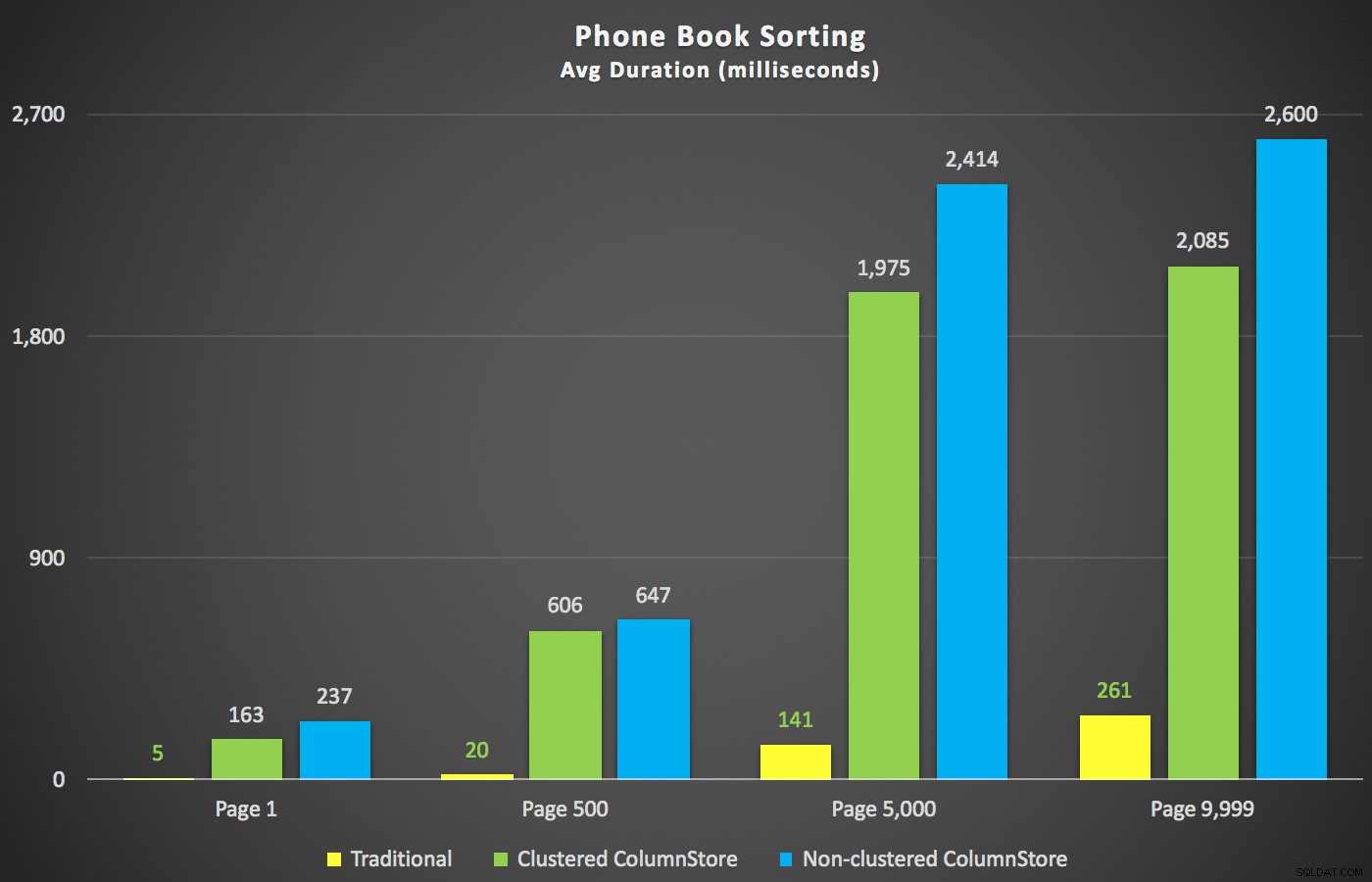
Die ColumnStore-Pläne hier sind nahezu Spiegelbilder der beiden oben gezeigten ColumnStore-Pläne für die nicht unterstützte Sortierung. Der Grund ist in beiden Fällen derselbe:teure Scans oder Sortierungen aufgrund eines fehlenden sortierungsunterstützenden Indexes.
Also habe ich als nächstes unterstützende „PhoneBook“-Indizes für die Tabellen mit den ColumnStore-Indizes erstellt, um zu sehen, ob ich in einem dieser Szenarien einen anderen Plan und/oder schnellere Ausführungszeiten erreichen könnte. Ich habe diese beiden Indizes erstellt und dann wieder neu erstellt:
NICHT EINGESCHLOSSENEN INDEX ERSTELLEN [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName])INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; NICHT EINGESCHLOSSENEN INDEX ERSTELLEN [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([Nachname],[Vorname])INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Hier waren die neuen Dauern:
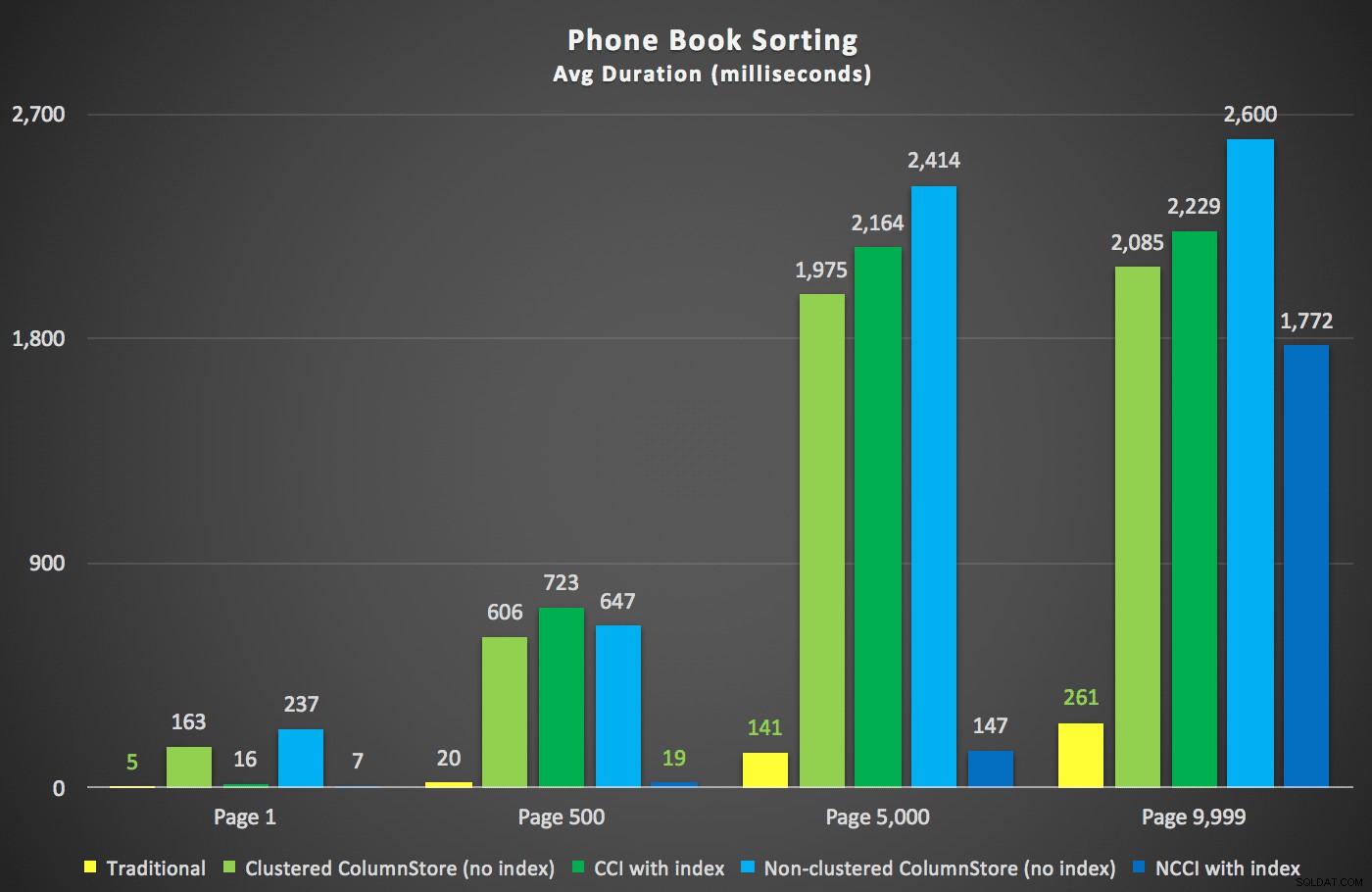
Am interessantesten ist hier, dass jetzt die Paging-Abfrage für die Tabelle mit dem nicht gruppierten ColumnStore-Index mit dem traditionellen Index Schritt zu halten scheint, bis wir über die Mitte der Tabelle hinausgehen. Wenn wir uns die Pläne ansehen, können wir sehen, dass auf Seite 5.000 ein herkömmlicher Index-Scan verwendet wird und der ColumnStore-Index vollständig ignoriert wird:
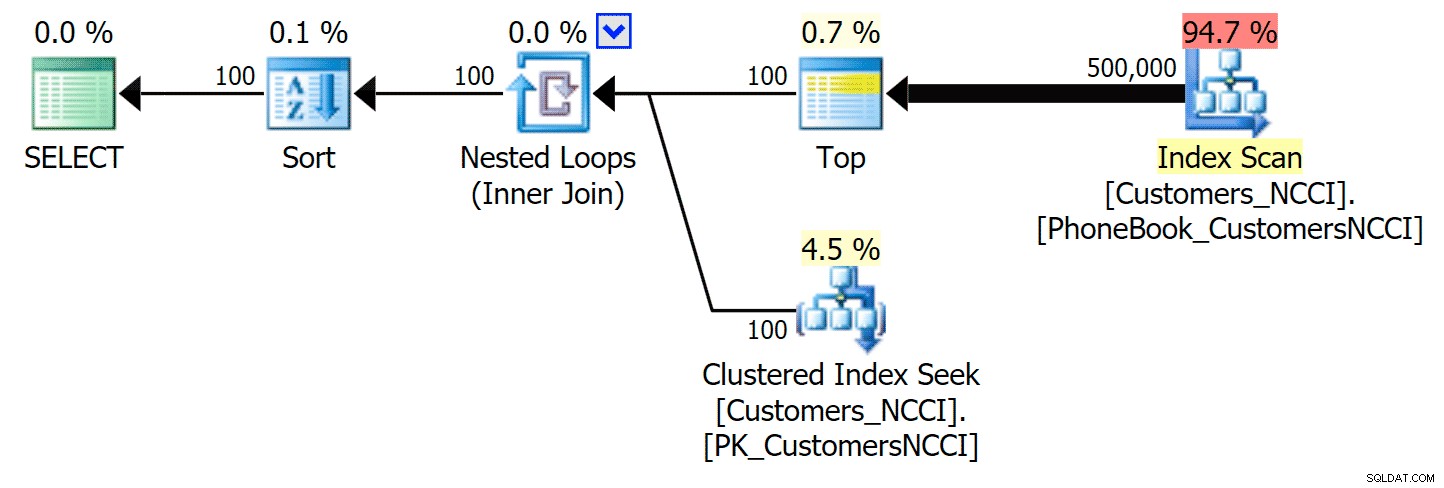 Telefonbuchplan ignoriert den nicht gruppierten ColumnStore-Index
Telefonbuchplan ignoriert den nicht gruppierten ColumnStore-Index
Aber irgendwo zwischen der Mitte von 5.000 Seiten und dem „Ende“ der Tabelle bei 9.999 Seiten hat der Optimierer eine Art Wendepunkt erreicht und – für genau dieselbe Abfrage – jetzt den nicht geclusterten ColumnStore-Index gescannt :
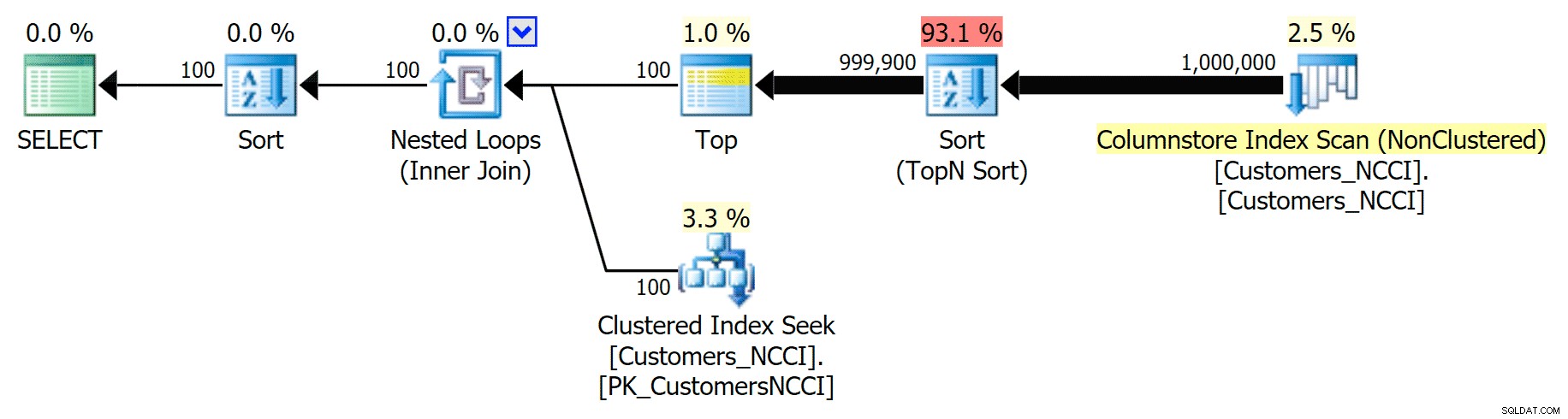 Tipps für den Telefonbuchplan und Verwendung des ColumnStore-Index
Tipps für den Telefonbuchplan und Verwendung des ColumnStore-Index
Dies stellt sich als nicht so gute Entscheidung des Optimierers heraus, hauptsächlich aufgrund der Kosten der Sortieroperation. Sie können sehen, wie viel besser die Dauer wird, wenn Sie den regulären Index andeuten:
-- ...;WITH pg AS ( SELECT CustomerID FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- Hinweis hier ORDER BY Nachname, Vorname OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize NUR ZEILEN )-- ...
Dies ergibt den folgenden Plan, der fast identisch mit dem ersten Plan oben ist (allerdings etwas höhere Kosten für den Scan, einfach weil mehr ausgegeben wird):
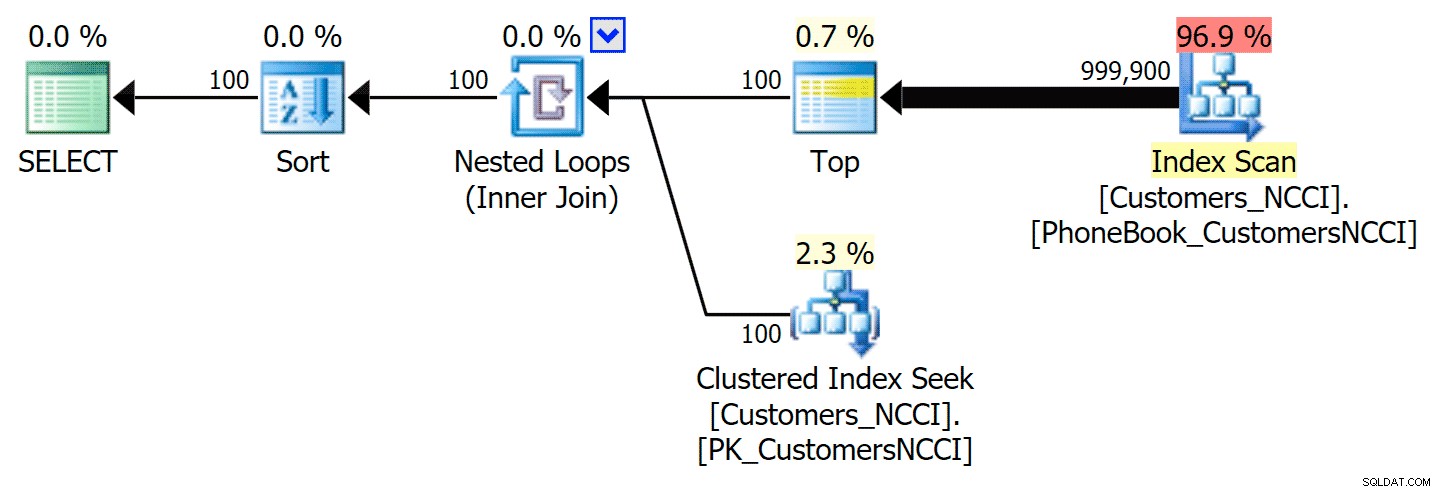 Telefonbuchplan mit angedeutetem Index
Telefonbuchplan mit angedeutetem Index
Sie können dasselbe mit OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) erreichen anstelle des expliziten Indexhinweises. Denken Sie nur daran, dass dies dasselbe ist, als ob der ColumnStore-Index überhaupt nicht vorhanden wäre.
Schlussfolgerung
Während es oben ein paar Grenzfälle gibt, in denen sich ein ColumnStore-Index (kaum) auszahlen könnte, scheint es mir nicht, dass sie für dieses spezielle Paginierungsszenario gut geeignet sind. Ich denke, was am wichtigsten ist, während ColumnStore aufgrund der Komprimierung erhebliche Platzeinsparungen aufweist, ist die Laufzeitleistung aufgrund der Sortieranforderungen nicht fantastisch (obwohl diese Sortierungen voraussichtlich im Stapelmodus ausgeführt werden, einer neuen Optimierung für SQL Server 2016).
Im Allgemeinen könnte dies mit viel mehr Zeit für Recherche und Tests auskommen; in Anlehnung an frühere Artikel wollte ich so wenig wie möglich ändern. Ich würde zum Beispiel gerne diesen Wendepunkt finden, und ich möchte auch anerkennen, dass dies nicht gerade umfangreiche Tests sind (aufgrund von VM-Größe und Speicherbeschränkungen), und dass ich Sie über viele davon raten ließ die Laufzeitmetriken (hauptsächlich der Kürze halber, aber ich weiß nicht, ob ein Diagramm von Lesevorgängen, die nicht immer proportional zur Dauer sind, es Ihnen wirklich sagen würde). Diese Tests setzen auch den Luxus von SSDs, ausreichend Speicher, einen immer warmen Cache und eine Einzelbenutzerumgebung voraus. Ich würde wirklich gerne eine größere Reihe von Tests mit mehr Daten auf größeren Servern mit langsameren Festplatten und Instanzen mit weniger Arbeitsspeicher durchführen, und das alles mit simulierter Parallelität.
Allerdings könnte dies auch nur ein Szenario sein, für dessen Lösung ColumnStore von vornherein nicht entwickelt wurde, da die zugrunde liegende Lösung mit herkömmlichen Indizes bereits ziemlich effizient darin ist, eine enge Reihe von Zeilen herauszuziehen – nicht gerade das Steuerhaus von ColumnStore. Vielleicht ist eine weitere Variable, die der Matrix hinzugefügt werden kann, die Seitengröße – alle oben genannten Tests ziehen 100 Zeilen auf einmal, aber was ist, wenn wir nach 10.000 oder 100.000 Zeilen auf einmal sind, unabhängig davon, wie groß die zugrunde liegende Tabelle ist?
Haben Sie eine Situation, in der Ihre OLTP-Workload einfach durch das Hinzufügen von ColumnStore-Indizes verbessert wurde? Ich weiß, dass sie für Workloads im Data-Warehouse-Stil konzipiert sind, aber wenn Sie anderswo Vorteile gesehen haben, würde ich gerne von Ihrem Szenario hören und sehen, ob ich Unterscheidungsmerkmale in meine Testumgebung integrieren kann.



