In Teil 1 und Teil 2 dieser Reihe habe ich die logischen oder konzeptionellen Aspekte benannter Tabellenausdrücke im Allgemeinen und abgeleitete Tabellen im Besonderen behandelt. In diesem und im nächsten Monat werde ich die Aspekte der physischen Verarbeitung abgeleiteter Tabellen behandeln. Erinnern Sie sich aus Teil 1 an die Physische Datenunabhängigkeit Prinzip der relationalen Theorie. Das relationale Modell und die darauf basierende Standardabfragesprache sollen sich nur mit den konzeptionellen Aspekten der Daten befassen und die physikalischen Implementierungsdetails wie Speicherung, Optimierung, Zugriff und Verarbeitung der Daten der Datenbankplattform (der Umsetzung ). Im Gegensatz zur konzeptionellen Behandlung der Daten, die auf einem mathematischen Modell und einer Standardsprache basiert und daher in den verschiedenen relationalen Datenbankverwaltungssystemen sehr ähnlich ist, basiert die physische Behandlung der Daten auf keinem Standard und ist daher tendenziell sehr plattformspezifisch sein. In meiner Berichterstattung über die physische Behandlung benannter Tabellenausdrücke in der Reihe konzentriere ich mich auf die Behandlung in Microsoft SQL Server und Azure SQL-Datenbank. Die physische Behandlung in anderen Datenbankplattformen kann ganz anders sein.
Erinnern Sie sich daran, dass der Auslöser dieser Serie eine gewisse Verwirrung war, die in der SQL Server-Community in Bezug auf benannte Tabellenausdrücke herrscht. Sowohl in Bezug auf die Terminologie als auch in Bezug auf die Optimierung. Ich habe in den ersten beiden Teilen der Serie einige Überlegungen zur Terminologie angesprochen und werde in zukünftigen Artikeln mehr darauf eingehen, wenn es um CTEs, Ansichten und Inline-TVFs geht. Was die Optimierung benannter Tabellenausdrücke betrifft, gibt es Verwirrung um die folgenden Punkte (ich erwähne hier abgeleitete Tabellen, da dies der Schwerpunkt dieses Artikels ist):
- Persistenz: Wird eine abgeleitete Tabelle irgendwo gespeichert? Wird es auf der Festplatte gespeichert und wie behandelt SQL Server den Speicher dafür?
- Spaltenprojektion: Wie funktioniert der Indexabgleich mit abgeleiteten Tabellen? Wenn beispielsweise eine abgeleitete Tabelle eine bestimmte Teilmenge von Spalten aus einer zugrunde liegenden Tabelle projiziert und die äußerste Abfrage eine Teilmenge der Spalten aus der abgeleiteten Tabelle projiziert, ist SQL Server intelligent genug, um eine optimale Indizierung basierend auf der letzten Teilmenge von Spalten zu ermitteln das braucht man eigentlich? Und was ist mit Berechtigungen; Benötigt der Benutzer Berechtigungen für alle Spalten, auf die in den inneren Abfragen verwiesen wird, oder nur auf die letzten, die tatsächlich benötigt werden?
- Mehrere Verweise auf Spaltenaliase: Wenn die abgeleitete Tabelle eine Ergebnisspalte hat, die auf einer nicht deterministischen Berechnung basiert, z. B. ein Aufruf der Funktion SYSDATETIME, und die äußere Abfrage mehrere Referenzen auf diese Spalte hat, wird die Berechnung nur einmal oder für jede äußere Referenz separat durchgeführt ?
- Entschachtelung/Substitution/Inlining: Entschachtelt oder integriert SQL Server die abgeleitete Tabellenabfrage? Das heißt, führt SQL Server einen Substitutionsprozess durch, bei dem der ursprünglich verschachtelte Code in eine Abfrage konvertiert wird, die direkt mit den Basistabellen übereinstimmt? Und wenn ja, gibt es eine Möglichkeit, SQL Server anzuweisen, diesen Entschachtelungsprozess zu vermeiden?
Dies sind alles wichtige Fragen, und die Antworten auf diese Fragen haben erhebliche Auswirkungen auf die Leistung, daher ist es eine gute Idee, ein klares Verständnis dafür zu haben, wie diese Elemente in SQL Server behandelt werden. Diesen Monat werde ich die ersten drei Punkte ansprechen. Über den vierten Punkt gibt es ziemlich viel zu sagen, also werde ich ihm nächsten Monat einen eigenen Artikel widmen (Teil 4).
In meinen Beispielen verwende ich eine Beispieldatenbank namens TSQLV5. Das Skript, das TSQLV5 erstellt und füllt, finden Sie hier und sein ER-Diagramm hier.
Persistenz
Einige Leute gehen intuitiv davon aus, dass SQL Server das Ergebnis des Tabellenausdrucksteils der abgeleiteten Tabelle (das Ergebnis der inneren Abfrage) in einer Arbeitstabelle speichert. Zum Zeitpunkt dieses Schreibens ist dies nicht der Fall; Da Persistenzüberlegungen jedoch die Wahl eines Anbieters sind, könnte Microsoft beschließen, dies in Zukunft zu ändern. Tatsächlich ist SQL Server in der Lage, Zwischenabfrageergebnisse als Teil der Abfrageverarbeitung in Arbeitstabellen (normalerweise in tempdb) zu speichern. Wenn es sich dafür entscheidet, sehen Sie eine Art Spool-Operator im Plan (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Die Entscheidung von SQL Server, etwas in eine Arbeitstabelle zu spoolen oder nicht, hat derzeit jedoch nichts mit Ihrer Verwendung benannter Tabellenausdrücke in der Abfrage zu tun. SQL Server spoolt manchmal Zwischenergebnisse aus Leistungsgründen, z. B. um wiederholte Arbeit zu vermeiden (obwohl derzeit nichts mit der Verwendung benannter Tabellenausdrücke zu tun hat), und manchmal aus anderen Gründen, z. B. zum Schutz vor Halloween.
Wie bereits erwähnt, werde ich nächsten Monat auf die Details der Entschachtelung abgeleiteter Tabellen eingehen. Fürs Erste reicht es zu sagen, dass SQL Server normalerweise einen Unnesting/Inlining-Prozess auf abgeleitete Tabellen anwendet, bei dem die verschachtelten Abfragen durch eine Abfrage der zugrunde liegenden Basistabellen ersetzt werden. Nun, ich vereinfache etwas. Es ist nicht so, dass SQL Server die ursprüngliche T-SQL-Abfragezeichenfolge mit den abgeleiteten Tabellen buchstäblich in eine neue Abfragezeichenfolge ohne diese konvertiert; Stattdessen wendet SQL Server Transformationen auf eine interne logische Struktur von Operatoren an, und das Ergebnis ist, dass die abgeleiteten Tabellen normalerweise effektiv entschachtelt werden. Wenn Sie sich einen Ausführungsplan für eine Abfrage mit abgeleiteten Tabellen ansehen, werden diese nicht erwähnt, da sie für die meisten Optimierungszwecke nicht vorhanden sind. Sie sehen Zugriff auf die physischen Strukturen, die die Daten für die zugrunde liegenden Basistabellen enthalten (Heap, B-Baum-Rowstore-Indizes und Columnstore-Indizes für plattenbasierte Tabellen und Baum- und Hash-Indizes für speicheroptimierte Tabellen).
Es gibt Fälle, die verhindern, dass SQL Server eine abgeleitete Tabelle entschachtelt, aber selbst in diesen Fällen speichert SQL Server das Ergebnis des Tabellenausdrucks nicht in einer Arbeitstabelle. Ich werde die Details zusammen mit Beispielen nächsten Monat bereitstellen.
Da SQL Server abgeleitete Tabellen nicht persistiert, sondern direkt mit den physischen Strukturen interagiert, die die Daten für die zugrunde liegenden Basistabellen enthalten, ist die Frage, wie der Speicher für abgeleitete Tabellen gehandhabt wird, strittig. Wenn die zugrunde liegenden Basistabellen plattenbasiert sind, müssen ihre relevanten Seiten im Pufferpool verarbeitet werden. Wenn die zugrunde liegenden Tabellen speicheroptimiert sind, müssen ihre relevanten speicherinternen Zeilen verarbeitet werden. Aber das ist nicht anders, als wenn Sie die zugrunde liegenden Tabellen direkt selbst abfragen, ohne abgeleitete Tabellen zu verwenden. Hier gibt es also nichts Besonderes. Wenn Sie abgeleitete Tabellen verwenden, muss SQL Server für diese keine besonderen Speicherüberlegungen anwenden. Für die meisten Zwecke der Abfrageoptimierung sind sie nicht vorhanden.
Wenn Sie einen Fall haben, in dem Sie das Ergebnis eines Zwischenschritts in einer Arbeitstabelle speichern müssen, müssen Sie temporäre Tabellen oder Tabellenvariablen verwenden – keine benannten Tabellenausdrücke.
Spaltenprojektion und ein Wort auf SELECT *
Projektion ist einer der ursprünglichen Operatoren der relationalen Algebra. Angenommen, Sie haben eine Relation R1 mit den Attributen x, y und z. Die Projektion von R1 auf eine Teilmenge seiner Attribute, z. B. x und z, ist eine neue Relation R2, deren Überschrift die Teilmenge der projizierten Attribute von R1 (in unserem Fall x und z) und deren Körper die Menge der Tupel ist gebildet aus der ursprünglichen Kombination projizierter Attributwerte aus den Tupeln von R1.
Erinnern Sie sich daran, dass der Körper einer Beziehung – da er eine Menge von Tupeln ist – per Definition keine Duplikate hat. Es versteht sich also von selbst, dass die Tupel der Ergebnisrelation die eindeutige Kombination von Attributwerten sind, die aus der ursprünglichen Relation projiziert werden. Denken Sie jedoch daran, dass der Hauptteil einer Tabelle in SQL eine Mehrfachmenge von Zeilen und keine Menge ist, und normalerweise löscht SQL doppelte Zeilen nicht, es sei denn, Sie weisen es an. Bei einer Tabelle R1 mit den Spalten x, y und z kann die folgende Abfrage potenziell doppelte Zeilen zurückgeben und folgt daher nicht der Semantik des Projektionsoperators der relationalen Algebra, eine Menge zurückzugeben:
SELECT x, z FROM R1;
Indem Sie eine DISTINCT-Klausel hinzufügen, eliminieren Sie doppelte Zeilen und folgen der Semantik der relationalen Projektion besser:
SELECT DISTINCT x, z FROM R1;
Natürlich gibt es einige Fälle, in denen Sie wissen, dass das Ergebnis Ihrer Abfrage unterschiedliche Zeilen enthält, ohne dass eine DISTINCT-Klausel erforderlich ist, z. B. wenn eine Teilmenge der Spalten, die Sie zurückgeben, einen Schlüssel aus der abgefragten Tabelle enthält. Wenn beispielsweise x ein Schlüssel in R1 ist, sind die beiden obigen Abfragen logisch äquivalent.
Erinnern Sie sich auf jeden Fall an die zuvor erwähnten Fragen zur Optimierung von Abfragen mit abgeleiteten Tabellen und Spaltenprojektion. Wie funktioniert der Indexabgleich? Wenn eine abgeleitete Tabelle eine bestimmte Teilmenge von Spalten aus einer zugrunde liegenden Tabelle projiziert und die äußerste Abfrage eine Teilmenge der Spalten aus der abgeleiteten Tabelle projiziert, ist SQL Server intelligent genug, um eine optimale Indizierung basierend auf der letzten Teilmenge von Spalten zu ermitteln, die tatsächlich vorhanden ist erforderlich? Und was ist mit Berechtigungen; Benötigt der Benutzer Berechtigungen für alle Spalten, auf die in den inneren Abfragen verwiesen wird, oder nur auf die letzten, die tatsächlich benötigt werden? Angenommen, die Tabellenausdrucksabfrage definiert eine Ergebnisspalte, die auf einer Berechnung basiert, aber die äußere Abfrage projiziert diese Spalte nicht. Wird die Berechnung überhaupt ausgewertet?
Beginnen wir mit der letzten Frage, versuchen wir es. Betrachten Sie die folgende Abfrage:
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
Wie zu erwarten, schlägt diese Abfrage mit einem Division-durch-Null-Fehler fehl:
Msg 8134, Level 16, State 1Dividieren durch Null Fehler aufgetreten.
Definieren Sie als Nächstes eine abgeleitete Tabelle mit dem Namen D basierend auf der obigen Abfrage und im äußeren Abfrageprojekt D nur für custid und city, etwa so:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; Wie bereits erwähnt, wendet SQL Server normalerweise die Aufhebung/Ersetzung an, und da es in dieser Abfrage nichts gibt, was die Aufhebung der Verschachtelung verhindert (mehr dazu im nächsten Monat), entspricht die obige Abfrage der folgenden Abfrage:
SELECT custid, city FROM Sales.Customers;
Auch hier vereinfache ich etwas zu sehr. Die Realität ist etwas komplexer als diese beiden Abfragen, die als wirklich identisch angesehen werden, aber ich werde nächsten Monat auf diese Komplexitäten eingehen. Der Punkt ist, dass der Ausdruck 1/0 nicht einmal im Ausführungsplan der Abfrage auftaucht und überhaupt nicht ausgewertet wird, sodass die obige Abfrage erfolgreich und ohne Fehler ausgeführt wird.
Dennoch muss der Tabellenausdruck gültig sein. Betrachten Sie beispielsweise die folgende Abfrage:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Obwohl die äußere Abfrage nur eine Spalte aus dem Gruppierungssatz der inneren Abfrage projiziert, ist die innere Abfrage nicht gültig, da sie versucht, Spalten zurückzugeben, die weder Teil des Gruppierungssatzes noch in einer Aggregatfunktion enthalten sind. Diese Abfrage schlägt mit folgendem Fehler fehl:
Msg 8120, Level 16, State 1Spalte „Sales.Customers.custid“ ist in der Auswahlliste ungültig, da sie weder in einer Aggregatfunktion noch in der GROUP BY-Klausel enthalten ist.
Als nächstes gehen wir die Index-Matching-Frage an. Wenn die äußere Abfrage nur eine Teilmenge der Spalten aus der abgeleiteten Tabelle projiziert, ist SQL Server intelligent genug, um den Indexabgleich nur basierend auf den zurückgegebenen Spalten durchzuführen (und natürlich auf allen anderen Spalten, die ansonsten eine sinnvolle Rolle spielen, wie z. Gruppierung usw.)? Aber bevor wir uns dieser Frage zuwenden, fragen Sie sich vielleicht, warum wir uns überhaupt damit beschäftigen. Warum sollten Sie die Rückgabespalten der inneren Abfrage haben, die die äußere Abfrage nicht benötigt?
Die Antwort ist einfach, den Code zu verkürzen, indem die innere Abfrage das berüchtigte SELECT * verwendet. Wir alle wissen, dass die Verwendung von SELECT * eine schlechte Praxis ist, aber das ist hauptsächlich der Fall, wenn es in der äußersten Abfrage verwendet wird. Was passiert, wenn Sie eine Tabelle mit einer bestimmten Überschrift abfragen und diese Überschrift später geändert wird? Die Anwendung könnte mit Fehlern enden. Selbst wenn Sie am Ende keine Fehler haben, könnten Sie am Ende unnötigen Netzwerkverkehr erzeugen, indem Sie Spalten zurückgeben, die die Anwendung nicht wirklich benötigt. Außerdem nutzen Sie die Indizierung in einem solchen Fall weniger optimal, da Sie die Chancen verringern, übereinstimmende abdeckende Indizes zu finden, die auf den wirklich benötigten Spalten basieren.
Allerdings fühle ich mich eigentlich ganz wohl dabei, SELECT * in einem Tabellenausdruck zu verwenden, da ich weiß, dass ich sowieso nur die wirklich benötigten Spalten in die äußerste Abfrage projizieren werde. Aus logischer Sicht ist das ziemlich sicher, mit einigen kleinen Vorbehalten, auf die ich gleich zurückkommen werde. Solange der Indexabgleich in einem solchen Fall optimal durchgeführt wird, und die gute Nachricht ist, dass es so ist.
Um dies zu demonstrieren, nehmen Sie an, dass Sie die Sales.Orders-Tabelle abfragen und die drei letzten Bestellungen für jeden Kunden zurückgeben müssen. Sie planen, eine abgeleitete Tabelle namens D basierend auf einer Abfrage zu definieren, die Zeilennummern (Ergebnisspalte rownum) berechnet, die nach custid partitioniert und nach orderdate DESC, orderid DESC sortiert sind. Die äußere Abfrage filtert nach D (relationale Einschränkung ) nur die Zeilen, in denen rownum kleiner oder gleich 3 ist, und Projekt D auf custid, orderdate, orderid und rownum. Jetzt hat Sales.Orders mehr Spalten als die, die Sie projizieren müssen, aber der Kürze halber möchten Sie, dass die innere Abfrage SELECT * plus die Berechnung der Zeilennummer verwendet. Das ist sicher und wird beim Index-Matching optimal gehandhabt.
Verwenden Sie den folgenden Code, um den optimalen abdeckenden Index zur Unterstützung Ihrer Abfrage zu erstellen:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Hier ist die Abfrage, die die vorliegende Aufgabe archiviert (wir nennen sie Abfrage 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Beachten Sie das SELECT * der inneren Abfrage und die explizite Spaltenliste der äußeren Abfrage.
Der Plan für diese Abfrage, wie er von SentryOne Plan Explorer gerendert wird, ist in Abbildung 1 dargestellt.
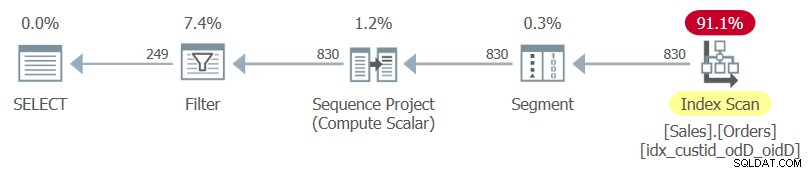 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Beachten Sie, dass der einzige Index, der in diesem Plan verwendet wird, der optimal abdeckende Index ist, den Sie gerade erstellt haben.
Wenn Sie nur die innere Abfrage markieren und ihren Ausführungsplan untersuchen, sehen Sie den verwendeten Clustered-Index der Tabelle, gefolgt von einer Sortieroperation.
Das sind also gute Neuigkeiten.
Was Berechtigungen betrifft, ist das eine andere Geschichte. Anders als beim Indexabgleich, bei dem der Index keine Spalten enthalten muss, auf die von den inneren Abfragen verwiesen wird, solange sie letztendlich nicht benötigt werden, müssen Sie über Berechtigungen für alle referenzierten Spalten verfügen.
Um dies zu demonstrieren, verwenden Sie den folgenden Code, um einen Benutzer namens user1 zu erstellen und einige Berechtigungen zuzuweisen (SELECT-Berechtigungen für alle Spalten von Sales.Customers und nur für die drei Spalten von Sales.Orders, die in der obigen Abfrage letztendlich relevant sind):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Führen Sie den folgenden Code aus, um sich als Benutzer1 auszugeben:
EXECUTE AS USER = 'user1';
Versuchen Sie, alle Spalten von Sales.Orders:
auszuwählenSELECT * FROM Sales.Orders;
Wie erwartet erhalten Sie die folgenden Fehler aufgrund fehlender Berechtigungen für einige der Spalten:
Msg 230, Level 14, State 1Die SELECT-Berechtigung wurde für die Spalte „empid“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230 , Ebene 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „requireddate“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „shippeddate“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „shipperid“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Ebene 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „Freight“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde für die Spalte „shipname“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde für die Spalte 'shipaddress' des Objekts 'Orders', Datenbank 'TSQLV5', Schema 'Sales' verweigert.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde für die Spalte „shipcity“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, State 1
The SELECT Berechtigung wurde für die Spalte „shipregion“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“ verweigert.
Msg 230, Ebene 14, Zustand 1
Die SELECT-Berechtigung war verweigert auf der Spalte 'shippostalcode' des Objekts 'Orders', Datenbank 'TSQLV5', Schema 'Sales'.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde verweigert die Spalte 'shipcountry' des Objekts 'Orders', Datenbank 'TSQLV5', Schema 'Sales'.
Probieren Sie die folgende Abfrage aus und projizieren und interagieren Sie nur mit Spalten, für die Benutzer1 Berechtigungen hat:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Dennoch erhalten Sie Spaltenberechtigungsfehler aufgrund fehlender Berechtigungen für einige der Spalten, auf die von der inneren Abfrage über ihr SELECT *:
verwiesen wird Msg 230, Level 14, State 1Die SELECT-Berechtigung wurde für die Spalte „empid“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230 , Ebene 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „requireddate“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „shippeddate“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „shipperid“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Ebene 14, Status 1
Die SELECT-Berechtigung wurde für die Spalte „Freight“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde für die Spalte „shipname“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde für die Spalte 'shipaddress' des Objekts 'Orders', Datenbank 'TSQLV5', Schema 'Sales' verweigert.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde für die Spalte „shipcity“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“, verweigert.
Msg 230, Level 14, State 1
The SELECT Berechtigung wurde für die Spalte „shipregion“ des Objekts „Orders“, Datenbank „TSQLV5“, Schema „Sales“ verweigert.
Msg 230, Ebene 14, Zustand 1
Die SELECT-Berechtigung war verweigert auf der Spalte 'shippostalcode' des Objekts 'Orders', Datenbank 'TSQLV5', Schema 'Sales'.
Msg 230, Level 14, State 1
Die SELECT-Berechtigung wurde verweigert die Spalte 'shipcountry' des Objekts 'Orders', Datenbank 'TSQLV5', Schema 'Sales'.
Wenn es in Ihrem Unternehmen tatsächlich üblich ist, Benutzern Berechtigungen nur für relevante Spalten zuzuweisen, mit denen sie interagieren müssen, wäre es sinnvoll, einen etwas längeren Code zu verwenden und die Spaltenliste sowohl in der inneren als auch in der äußeren Abfrage explizit anzugeben. so:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Diesmal läuft die Abfrage fehlerfrei.
Eine andere Variante, die erfordert, dass der Benutzer nur Berechtigungen für die relevanten Spalten hat, besteht darin, die Spaltennamen in der SELECT-Liste der inneren Abfrage explizit anzugeben und SELECT * in der äußeren Abfrage zu verwenden, etwa so:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Auch diese Abfrage läuft ohne Fehler. Ich sehe diese Version jedoch als fehleranfällig an, falls später einige Änderungen in einer inneren Verschachtelungsebene vorgenommen werden. Wie bereits erwähnt, ist es für mich die beste Vorgehensweise, die Spaltenliste in der äußersten Abfrage explizit anzugeben. Solange Sie also keine Bedenken wegen fehlender Berechtigungen für einige der Spalten haben, fühle ich mich wohl mit SELECT * in inneren Abfragen, aber einer expliziten Spaltenliste in der äußersten Abfrage. Wenn das Anwenden bestimmter Spaltenberechtigungen im Unternehmen gängige Praxis ist, ist es am besten, die Spaltennamen auf allen Verschachtelungsebenen einfach explizit anzugeben. Wohlgemerkt, die explizite Angabe von Spaltennamen auf allen Verschachtelungsebenen ist eigentlich obligatorisch, wenn Ihre Abfrage in einem schemagebundenen Objekt verwendet wird, da die Schemabindung die Verwendung von SELECT * an keiner Stelle in der Abfrage zulässt.
Führen Sie an dieser Stelle den folgenden Code aus, um den Index zu entfernen, den Sie zuvor auf Sales.Orders erstellt haben:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
Es gibt einen anderen Fall mit einem ähnlichen Dilemma bezüglich der Legitimität der Verwendung von SELECT *; in der inneren Abfrage des EXISTS-Prädikats.
Betrachten Sie die folgende Abfrage (wir nennen sie Abfrage 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); Der Plan für diese Abfrage ist in Abbildung 2 dargestellt.
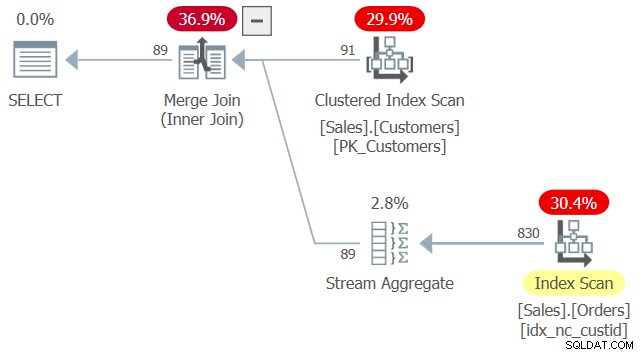 Abbildung 2:Plan für Abfrage 2
Abbildung 2:Plan für Abfrage 2
Beim Anwenden des Indexabgleichs stellte der Optimierer fest, dass der Index idx_nc_custid ein abdeckender Index für Sales.Orders ist, da er die Spalte custid enthält – die einzig wirklich relevante Spalte in dieser Abfrage. Und das, obwohl dieser Index außer custid keine weitere Spalte enthält und die innere Abfrage im EXISTS-Prädikat SELECT * lautet. Bisher scheint das Verhalten der Verwendung von SELECT * in abgeleiteten Tabellen ähnlich zu sein.
Der Unterschied zu dieser Abfrage besteht darin, dass sie fehlerfrei ausgeführt wird, obwohl „user1“ keine Berechtigungen für einige der Spalten von „Sales.Orders“ hat. Es gibt ein Argument, um zu rechtfertigen, dass hier keine Berechtigungen für alle Spalten erforderlich sind. Schließlich muss das EXISTS-Prädikat nur prüfen, ob übereinstimmende Zeilen vorhanden sind, sodass die SELECT-Liste der inneren Abfrage wirklich bedeutungslos ist. Es wäre wahrscheinlich am besten gewesen, wenn SQL in einem solchen Fall überhaupt keine SELECT-Liste benötigt hätte, aber dieses Schiff ist bereits abgefahren. Die gute Nachricht ist, dass die SELECT-Liste effektiv ignoriert wird – sowohl in Bezug auf den Indexabgleich als auch in Bezug auf die erforderlichen Berechtigungen.
Es scheint auch, dass es einen weiteren Unterschied zwischen abgeleiteten Tabellen und EXISTS gibt, wenn SELECT * in der inneren Abfrage verwendet wird. Erinnern Sie sich an diese Abfrage von früher im Artikel:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Wenn Sie sich erinnern, hat dieser Code einen Fehler generiert, da die innere Abfrage ungültig ist.
Probieren Sie dieselbe innere Abfrage aus, nur dieses Mal im EXISTS-Prädikat (wir nennen diese Anweisung 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; Seltsamerweise betrachtet SQL Server diesen Code als gültig und wird erfolgreich ausgeführt. Der Plan für diesen Code ist in Abbildung 3 dargestellt.
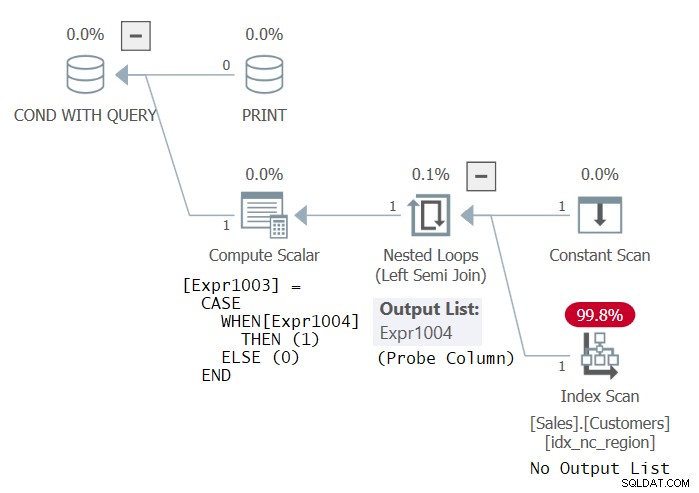 Abbildung 3:Plan für Anweisung 3
Abbildung 3:Plan für Anweisung 3
Dieser Plan ist identisch mit dem Plan, den Sie erhalten würden, wenn die innere Abfrage nur SELECT * FROM Sales.Customers (ohne GROUP BY) wäre. Schließlich prüfen Sie, ob Gruppen vorhanden sind, und wenn es Zeilen gibt, gibt es natürlich auch Gruppen. Wie auch immer, ich denke, dass die Tatsache, dass SQL Server diese Abfrage als gültig betrachtet, ein Fehler ist. Sicherlich sollte der SQL-Code gültig sein! Aber ich kann verstehen, warum einige argumentieren könnten, dass die SELECT-Liste in der EXISTS-Abfrage ignoriert werden soll. Auf jeden Fall verwendet der Plan einen sondierten linken Semi-Join, der keine Spalten zurückgeben muss, sondern nur eine Tabelle sondiert, um zu prüfen, ob Zeilen vorhanden sind. Der Index für Kunden kann ein beliebiger Index sein.
An diesem Punkt können Sie den folgenden Code ausführen, um die Identität von Benutzer1 zu beenden und ihn zu löschen:
REVERT; DROP USER IF EXISTS user1;
Zurück zu der Tatsache, dass ich es für eine bequeme Praxis halte, SELECT * in inneren Verschachtelungsebenen zu verwenden, je mehr Ebenen Sie haben, desto mehr verkürzt und vereinfacht diese Praxis Ihren Code. Hier ist ein Beispiel mit zwei Verschachtelungsebenen:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; Es gibt Fälle, in denen diese Praxis nicht angewendet werden kann. Zum Beispiel, wenn die innere Abfrage Tabellen mit gemeinsamen Spaltennamen verbindet, wie im folgenden Beispiel:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Sowohl Sales.Customers als auch Sales.Orders haben eine Spalte namens custid. Sie verwenden einen Tabellenausdruck, der auf einem Join zwischen den beiden Tabellen basiert, um die abgeleitete Tabelle D zu definieren. Denken Sie daran, dass die Überschrift einer Tabelle aus einer Reihe von Spalten besteht und Sie als Gruppe keine doppelten Spaltennamen haben dürfen. Daher schlägt diese Abfrage mit folgendem Fehler fehl:
Msg 8156, Level 16, State 1Die Spalte „custid“ wurde mehrfach für „D“ angegeben.
Hier müssen Sie die Spaltennamen in der inneren Abfrage explizit angeben und sicherstellen, dass Sie entweder custid nur aus einer der Tabellen zurückgeben oder den Ergebnisspalten eindeutige Spaltennamen zuweisen, falls Sie beide zurückgeben möchten. Häufiger würden Sie den früheren Ansatz verwenden, etwa so:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Auch hier könnten Sie mit den Spaltennamen in der inneren Abfrage explizit sein und SELECT * in der äußeren Abfrage verwenden, etwa so:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Aber wie ich bereits erwähnt habe, halte ich es für eine schlechte Praxis, Spaltennamen in der äußersten Abfrage nicht explizit anzugeben.
Mehrere Verweise auf Spaltenaliase
Fahren wir mit dem nächsten Punkt fort – mehreren Verweisen auf abgeleitete Tabellenspalten. Wenn die abgeleitete Tabelle eine Ergebnisspalte hat, die auf einer nicht deterministischen Berechnung basiert, und die äußere Abfrage mehrere Verweise auf diese Spalte hat, wird die Berechnung dann nur einmal oder separat für jeden Verweis ausgewertet?
Beginnen wir damit, dass mehrere Verweise auf dieselbe nichtdeterministische Funktion in einer Abfrage unabhängig voneinander ausgewertet werden sollen. Betrachten Sie die folgende Abfrage als Beispiel:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Dieser Code generiert die folgende Ausgabe, die zwei verschiedene GUIDs zeigt:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Wenn Sie dagegen eine abgeleitete Tabelle mit einer Spalte haben, die auf einer nicht deterministischen Berechnung basiert, und die äußere Abfrage mehrere Verweise auf diese Spalte enthält, soll die Berechnung nur einmal ausgewertet werden. Betrachten Sie die folgende Abfrage (wir nennen diese Abfrage 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
Der Plan für diese Abfrage ist in Abbildung 4 dargestellt.
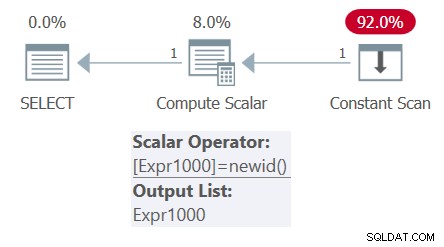 Abbildung 4:Plan für Abfrage 4
Abbildung 4:Plan für Abfrage 4
Beachten Sie, dass der Plan nur einen Aufruf der NEWID-Funktion enthält. Dementsprechend zeigt die Ausgabe zweimal dieselbe GUID:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
Daher sind die beiden obigen Abfragen logisch nicht äquivalent, und es gibt Fälle, in denen kein Inlining/Ersetzung stattfindet.
Bei einigen nichtdeterministischen Funktionen ist es etwas schwieriger zu zeigen, dass mehrere Aufrufe in einer Abfrage separat behandelt werden. Nehmen Sie als Beispiel die Funktion SYSDATETIME. Es hat eine Genauigkeit von 100 Nanosekunden. Wie hoch ist die Wahrscheinlichkeit, dass eine Abfrage wie die folgende tatsächlich zwei verschiedene Werte anzeigt?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Wenn Sie sich langweilen, können Sie wiederholt F5 drücken, bis es passiert. Wenn Sie wichtigere Dinge mit Ihrer Zeit zu tun haben, ziehen Sie es vielleicht vor, eine Schleife wie folgt auszuführen:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; Als ich beispielsweise diesen Code ausführte, erhielt ich 1971.
Wenn Sie sicherstellen möchten, dass die nicht deterministische Funktion nur einmal aufgerufen wird, und sich auf denselben Wert in mehreren Abfragereferenzen verlassen möchten, stellen Sie sicher, dass Sie einen Tabellenausdruck mit einer Spalte basierend auf dem Funktionsaufruf definieren und mehrere Referenzen auf diese Spalte haben aus der äußeren Abfrage, etwa so (wir nennen diese Abfrage 5):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
Der Plan für diese Abfrage ist in Abbildung 5 dargestellt.
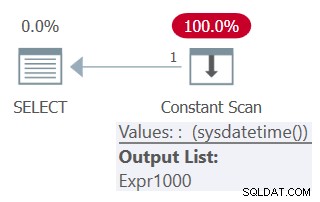 Abbildung 5:Plan für Abfrage 5
Abbildung 5:Plan für Abfrage 5
Notice in the plan that the function is invoked only once.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; Zusammenfassung
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.