Hochverfügbarkeit ist ein hoher Prozentsatz der Zeit, in der das System arbeitet und entsprechend den Geschäftsanforderungen reagiert. Bei Produktionsdatenbanksystemen hat es in der Regel die höchste Priorität, sie nahe bei 100 % zu halten. Wir erstellen Datenbankcluster, um alle Single Point of Failure zu eliminieren. Wenn eine Instanz nicht verfügbar ist, sollte ein anderer Knoten in der Lage sein, die Arbeitslast zu übernehmen und von dort aus weiterzumachen. In einer perfekten Welt würde ein Datenbank-Cluster all unsere Systemverfügbarkeitsprobleme lösen. Auch wenn auf dem Papier alles gut aussieht, sieht die Realität leider oft anders aus. Wo kann also etwas schief gehen?
Transaktionsdatenbanksysteme verfügen über ausgeklügelte Speicher-Engines. Daten über mehrere Knoten hinweg konsistent zu halten, macht diese Aufgabe viel schwieriger. Clustering führt eine Reihe neuer Variablen ein, die stark vom Netzwerk und der zugrunde liegenden Infrastruktur abhängen. Es ist nicht ungewöhnlich, dass eine eigenständige Datenbankinstanz, die auf einem einzelnen Knoten einwandfrei lief, in einer Clusterumgebung plötzlich eine schlechte Leistung erbringt.
Unter den Faktoren, die die Verfügbarkeit von Clustern beeinträchtigen können, spielen Latenzprobleme eine entscheidende Rolle. Wie hoch ist jedoch die Latenz? Bezieht es sich nur auf das Netzwerk?
Der Begriff "Latenz" bezieht sich tatsächlich auf verschiedene Arten von Verzögerungen, die bei der Verarbeitung von Daten auftreten. So lange dauert es, bis eine Information von einer Phase zur nächsten gelangt.
In diesem Blogbeitrag sehen wir uns die beiden wichtigsten Hochverfügbarkeitslösungen für MySQL und MariaDB an und wie sie jeweils von Latenzproblemen betroffen sein können.
Am Ende des Artikels werfen wir einen Blick auf moderne Load Balancer und diskutieren, wie sie Ihnen helfen können, einige Arten von Latenzproblemen zu lösen.
In einem früheren Artikel schrieb mein Kollege Krzysztof Książek über „Dealing with Unreliable Networks When Crafting an HA Solution for MySQL or MariaDB“. Sie werden Tipps finden, die Ihnen helfen können, Ihre produktionsreife HA-Architektur zu entwerfen und einige der hier beschriebenen Probleme zu vermeiden.
Master-Slave-Replikation für Hochverfügbarkeit.
Die MySQL-Master-Slave-Replikation ist wahrscheinlich der beliebteste Datenbank-Cluster-Typ auf dem Planeten. Eines der wichtigsten Dinge, die Sie beim Ausführen Ihres Master-Slave-Replikationsclusters überwachen möchten, ist die Slave-Verzögerung. Abhängig von Ihren Anwendungsanforderungen und der Art und Weise, wie Sie Ihre Datenbank nutzen, kann die Replikationslatenz (Slave-Verzögerung) bestimmen, ob die Daten vom Slave-Knoten gelesen werden können oder nicht. Daten, die auf dem Master festgeschrieben, aber auf einem asynchronen Slave noch nicht verfügbar sind, bedeuten, dass der Slave einen älteren Zustand hat. Wenn es nicht in Ordnung ist, von einem Slave zu lesen, müssten Sie zum Master gehen, und das kann die Anwendungsleistung beeinträchtigen. Im schlimmsten Fall ist Ihr System nicht in der Lage, die gesamte Arbeitslast auf einem Master zu bewältigen.
Slave-Lag und veraltete Daten
Um den Status der Master-Slave-Replikation zu überprüfen, sollten Sie mit dem folgenden Befehl beginnen:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Anhand der obigen Informationen können Sie bestimmen, wie gut die allgemeine Replikationslatenz ist. Je niedriger der Wert, den Sie in "Seconds_Behind_Master" sehen, desto besser ist die Datenübertragungsgeschwindigkeit für die Replikation.
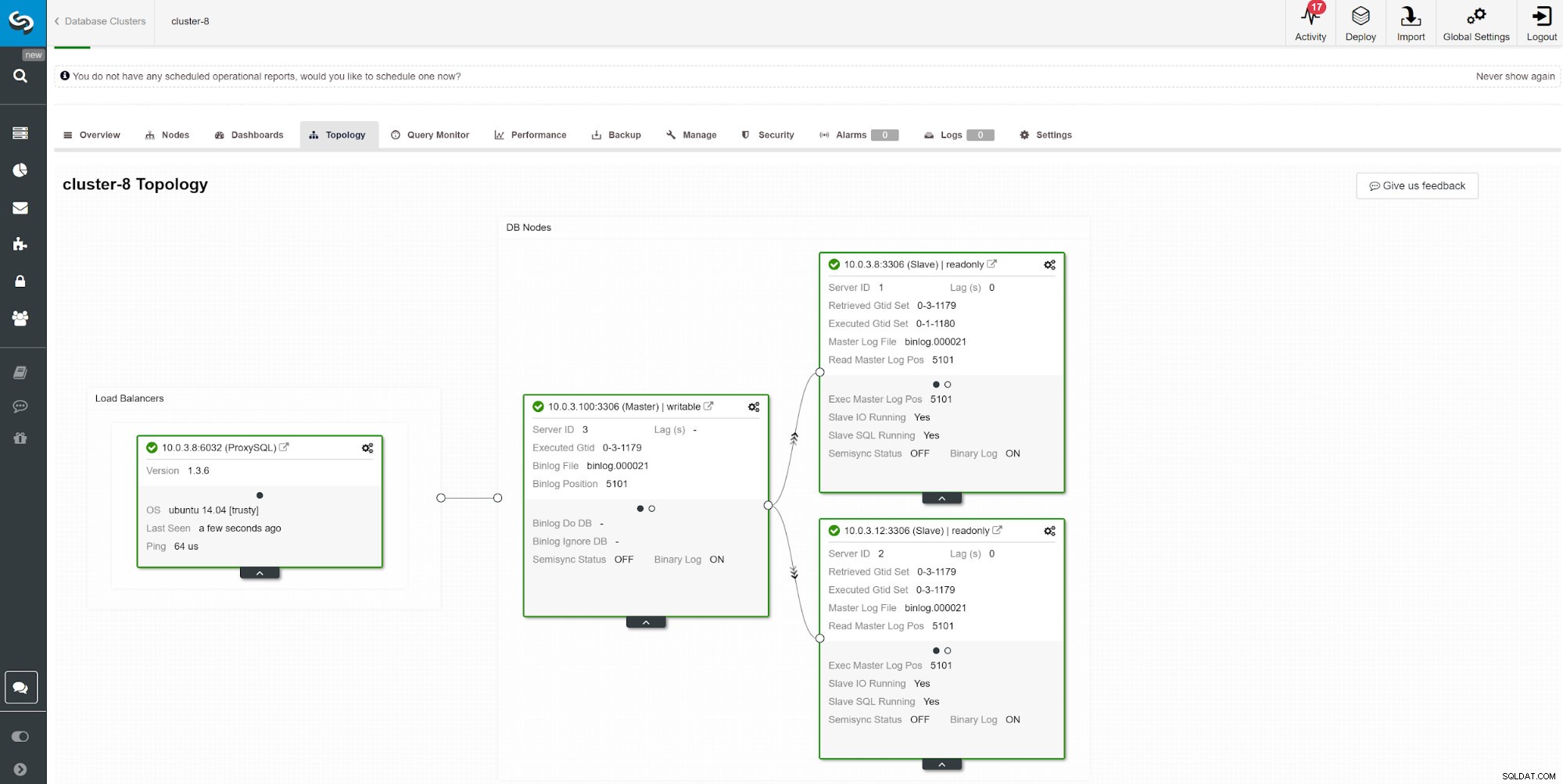 Eine andere Möglichkeit zur Überwachung der Slave-Verzögerung ist die Verwendung der ClusterControl-Replikationsüberwachung. In diesem Screenshot sehen wir den Replikationsstatus des asymchoronen Master-Slave (2x) Clusters mit ProxySQL.
Eine andere Möglichkeit zur Überwachung der Slave-Verzögerung ist die Verwendung der ClusterControl-Replikationsüberwachung. In diesem Screenshot sehen wir den Replikationsstatus des asymchoronen Master-Slave (2x) Clusters mit ProxySQL. Es gibt eine Reihe von Dingen, die sich auf die Replikationszeit auswirken können. Am offensichtlichsten ist der Netzwerkdurchsatz und wie viele Daten Sie übertragen können. MySQL verfügt über mehrere Konfigurationsoptionen, um den Replikationsprozess zu optimieren. Die wesentlichen replikationsbezogenen Parameter sind:
- Parallel anwenden
- Logischer Taktalgorithmus
- Komprimierung
- Selektive Master-Slave-Replikation
- Replikationsmodus
Parallele Anwendung
Es ist nicht ungewöhnlich, die Replikationsoptimierung mit der Aktivierung der parallelen Prozessanwendung zu starten. Der Grund dafür ist, dass MySQL standardmäßig mit sequentiellem Binärlog arbeitet und ein typischer Datenbankserver mit mehreren zu verwendenden CPUs kommt.
Um die sequenzielle Protokollierung zu umgehen, bieten sowohl MariaDB als auch MySQL parallele Replikation an. Die Implementierung kann je nach Anbieter und Version unterschiedlich sein. Z.B. MySQL 5.6 bietet parallele Replikation, solange ein Schema die Abfragen trennt, während MariaDB (ab Version 10.0) und MySQL 5.7 beide die parallele Replikation über Schemas hinweg handhaben können. Unterschiedliche Anbieter und Versionen haben ihre Einschränkungen und Funktionen, überprüfen Sie also immer die Dokumentation.
Das Ausführen von Abfragen über parallele Slave-Threads kann Ihren Replikationsstrom beschleunigen, wenn Sie viel schreiben. Wenn Sie es jedoch nicht sind, ist es am besten, sich an die traditionelle Single-Thread-Replikation zu halten. Um die parallele Verarbeitung zu aktivieren, ändern Sie die slave_parallel_workers auf die Anzahl der CPU-Threads, die Sie in den Prozess einbeziehen möchten. Es wird empfohlen, den Wert unter der Anzahl der verfügbaren CPU-Threads zu halten.
Die parallele Replikation funktioniert am besten mit den Gruppen-Commits. Um zu überprüfen, ob Gruppen-Commits stattfinden, führen Sie die folgende Abfrage aus.
show global status like 'binlog_%commits';Je größer das Verhältnis zwischen diesen beiden Werten, desto besser.
Logische Uhr
Der slave_parallel_type=LOGICAL_CLOCK ist eine Implementierung eines Lamport-Taktalgorithmus. Bei Verwendung eines Multithread-Slaves gibt diese Variable die Methode an, die verwendet wird, um zu entscheiden, welche Transaktionen parallel auf dem Slave ausgeführt werden dürfen. Die Variable hat keine Auswirkung auf Slaves, für die Multithreading nicht aktiviert ist, also stellen Sie sicher, dass slave_parallel_workers höher als 0 eingestellt ist.
MariaDB-Benutzer sollten auch den in Version 10.1.3 eingeführten optimistischen Modus überprüfen, da er möglicherweise auch bessere Ergebnisse liefert.
GTID
MariaDB wird mit einer eigenen Implementierung von GTID geliefert. Die Sequenz von MariaDB besteht aus einer Domäne, einem Server und einer Transaktion. Domänen ermöglichen die Replikation aus mehreren Quellen mit eindeutiger ID. Verschiedene Domänen-IDs können verwendet werden, um den Teil der Daten außerhalb der Reihenfolge (parallel) zu replizieren. Solange es für Ihre Anwendung in Ordnung ist, kann dies die Replikationslatenz verringern.
Eine ähnliche Technik gilt für MySQL 5.7, das auch den Multisource-Master und unabhängige Replikationskanäle verwenden kann.
Komprimierung
Die CPU-Leistung wird im Laufe der Zeit immer günstiger, daher könnte die Verwendung für die Binlog-Komprimierung eine gute Option für viele Datenbankumgebungen sein. Der Parameter slave_compressed_protocol weist MySQL an, die Komprimierung zu verwenden, wenn Master und Slave dies unterstützen. Standardmäßig ist dieser Parameter deaktiviert.
Ab MariaDB 10.2.3 können ausgewählte Ereignisse im Binärlog optional komprimiert werden, um die Netzwerkübertragungen zu sparen.
Replikationsformate
MySQL bietet mehrere Replikationsmodi. Die Auswahl des richtigen Replikationsformats trägt dazu bei, die Zeit zum Übertragen von Daten zwischen den Cluster-Knoten zu minimieren.
Multimaster-Replikation für hohe Verfügbarkeit
Einige Anwendungen können es sich nicht leisten, mit veralteten Daten zu arbeiten.
In solchen Fällen möchten Sie möglicherweise die Konsistenz über die Knoten hinweg mit synchroner Replikation erzwingen. Um Daten synchron zu halten, ist ein zusätzliches Plugin erforderlich, und für einige ist Galera Cluster die beste Lösung auf dem Markt.
Der Galera-Cluster wird mit der wsrep-API geliefert, die dafür verantwortlich ist, Transaktionen an alle Knoten zu übertragen und sie gemäß einer clusterweiten Reihenfolge auszuführen. Dadurch wird die Ausführung nachfolgender Abfragen blockiert, bis der Knoten alle Write-Sets aus seiner Applikator-Warteschlange angewendet hat. Es ist zwar eine gute Lösung für Konsistenz, aber Sie können auf einige architektonische Einschränkungen stoßen. Die häufigsten Latenzprobleme können zusammenhängen mit:
- Der langsamste Knoten im Cluster
- Horizontale Skalierung und Schreibvorgänge
- Geolokalisierte Cluster
- Hoher Ping
- Transaktionsgröße
Der langsamste Knoten im Cluster
Die Schreibleistung des Clusters darf standardmäßig nicht höher sein als die Leistung des langsamsten Knotens im Cluster. Beginnen Sie Ihre Clusterüberprüfung, indem Sie die Maschinenressourcen überprüfen und die Konfigurationsdateien überprüfen, um sicherzustellen, dass sie alle mit denselben Leistungseinstellungen ausgeführt werden.
Parallelisierung
Parallele Threads garantieren keine bessere Leistung, können aber die Synchronisierung neuer Knoten mit dem Cluster beschleunigen. Der Status wsrep_cert_deps_distance sagt uns den möglichen Parallelisierungsgrad. Es ist der Wert des durchschnittlichen Abstands zwischen den höchsten und niedrigsten Seqno-Werten, die möglicherweise parallel angewendet werden können. Sie können die Statusvariable wsrep_cert_deps_distance verwenden, um die maximal mögliche Anzahl von Slave-Threads zu bestimmen.
Horizontale Skalierung
Durch das Hinzufügen weiterer Knoten im Cluster haben wir weniger Punkte, die ausfallen könnten; Die Informationen müssen jedoch mehrere Instanzen durchlaufen, bis sie festgeschrieben werden, was die Antwortzeiten vervielfacht. Wenn Sie skalierbare Schreibvorgänge benötigen, ziehen Sie eine auf Sharding basierende Architektur in Betracht. Eine gute Lösung kann eine Spider-Speicher-Engine sein.
In einigen Fällen können Sie zur Reduzierung der von den Cluster-Knoten gemeinsam genutzten Informationen in Betracht ziehen, jeweils nur einen Writer zu verwenden. Es ist relativ einfach zu implementieren, wenn ein Load Balancer verwendet wird. Wenn Sie dies manuell tun, stellen Sie sicher, dass Sie über ein Verfahren zum Ändern des DNS-Werts verfügen, wenn Ihr Writer-Knoten ausfällt.
Geolokalisierte Cluster
Obwohl Galera Cluster synchron ist, ist es möglich, einen Galera Cluster über Rechenzentren hinweg einzusetzen. Synchrone Replikation wie MySQL Cluster (NDB) implementiert ein zweiphasiges Commit, bei dem Nachrichten in einer „Vorbereitungsphase“ an alle Knoten in einem Cluster gesendet werden und ein weiterer Satz von Nachrichten in einer „Commit“-Phase gesendet wird. Dieser Ansatz ist aufgrund der Latenzen beim Senden von Nachrichten zwischen Knoten normalerweise nicht für geografisch unterschiedliche Knoten geeignet.
Hoher Ping
Galera Cluster mit den Standardeinstellungen kommt mit hoher Netzwerklatenz nicht gut zurecht. Wenn Sie ein Netzwerk mit einem Knoten haben, der eine hohe Ping-Zeit anzeigt, sollten Sie die Parameter evs.send_window und evs.user_send_window ändern. Diese Variablen definieren die maximale Anzahl von Datenpaketen, die gleichzeitig repliziert werden. Für WAN-Setups kann die Variable auf einen erheblich höheren Wert als den Standardwert von 2 gesetzt werden. Üblicherweise wird sie auf 512 gesetzt. Diese Parameter sind Teil von wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Transaktionsgröße
Eines der Dinge, die Sie beim Ausführen von Galera Cluster berücksichtigen müssen, ist die Größe der Transaktion. Das Gleichgewicht zwischen Transaktionsgröße, Leistung und Galera-Zertifizierungsprozess zu finden, ist etwas, das Sie in Ihrer Bewerbung einschätzen müssen. Weitere Informationen dazu finden Sie im Artikel How to Improve Performance of Galera Cluster for MySQL or MariaDB von Ashraf Sharif.
Kausale Konsistenz-Lesevorgänge für Load Balancer
Selbst mit dem minimierten Risiko von Datenlatenzproblemen kann die standardmäßige asynchrone MySQL-Replikation keine Konsistenz garantieren. Es ist immer noch möglich, dass die Daten noch nicht auf den Slave repliziert wurden, während Ihre Anwendung sie von dort liest. Die synchrone Replikation kann dieses Problem lösen, weist jedoch Architektureinschränkungen auf und entspricht möglicherweise nicht Ihren Anwendungsanforderungen (z. B. intensive Massenschreibvorgänge). Wie kann man es also überwinden?
Der erste Schritt, um das Lesen veralteter Daten zu vermeiden, besteht darin, die Anwendung auf die Replikationsverzögerung aufmerksam zu machen. Es wird normalerweise in Anwendungscode programmiert. Glücklicherweise gibt es moderne Datenbank-Load-Balancer mit Unterstützung für adaptives Query-Routing auf Basis von GTID-Tracking. Die beliebtesten sind ProxySQL und Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader ermöglicht es ProxySQL in Echtzeit zu wissen, welche GTID auf jedem MySQL-Server, Slaves und Master selbst ausgeführt wurde. Dadurch weiß ProxySQL sofort, auf welchem Server die Abfrage ausgeführt werden kann, wenn ein Client einen Lesevorgang ausführt, der Lesevorgänge mit kausaler Konsistenz bereitstellen muss. Wenn die Schreibvorgänge aus irgendeinem Grund noch nicht auf einem Slave ausgeführt wurden, weiß ProxySQL, dass der Schreiber auf dem Master ausgeführt wurde, und sendet den Lesevorgang dorthin.
Maxscale 2.3
MariaDB hat gelegentliche Lesevorgänge in Maxscale 2.3.0 eingeführt. Die Funktionsweise ähnelt ProxySQL 2.0. Wenn causal_reads aktiviert sind, werden alle nachfolgenden Lesevorgänge, die auf Slave-Servern durchgeführt werden, grundsätzlich so durchgeführt, dass Replikationsverzögerungen die Ergebnisse nicht beeinflussen. Wenn der Slave den Master nicht innerhalb der konfigurierten Zeit eingeholt hat, wird die Abfrage beim Master wiederholt.