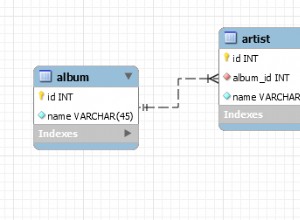
Indizes
Erstellen Sie Indizes auf x.id und y.id - die Sie wahrscheinlich bereits haben, wenn dies Ihre Primärschlüssel sind.
Ein mehrspaltiger Index kann auch hilfreich sein, insbesondere bei Nur-Index-Scans
auf Seite 9.2+:
CREATE INDEX y_mult_idx ON y (id DESC, val)
In meinen Tests wurde dieser Index jedoch zunächst nicht verwendet. Musste (ansonsten sinnlos) val hinzufügen bis ORDER BY um den Abfrageplaner davon zu überzeugen, dass die Sortierreihenfolge übereinstimmt. Siehe Abfrage 3 .
Der Index macht in diesem synthetischen Setup kaum einen Unterschied. Aber für Tabellen mit mehr Spalten wird val abgerufen aus dem Tisch wird immer teurer, wodurch der "deckende" Index attraktiver wird.
Abfragen
1) Einfach
SELECT DISTINCT ON (x.id)
x.id, y.val
FROM x
JOIN y ON y.id <= x.id
ORDER BY x.id, y.id DESC;
Mehr Erklärung für die Technik mit DISTINCT in dieser verwandten Antwort:
Ich habe einige Tests durchgeführt, weil ich den Verdacht hatte, dass die erste Abfrage nicht gut skalieren würde. Es ist schnell mit einem kleinen Tisch, aber nicht gut mit größeren Tischen. Postgres optimiert den Plan nicht und beginnt mit einem (begrenzten) Cross-Join mit Kosten von O(N²) .
2) Schnell
Diese Abfrage ist immer noch ziemlich einfach und skaliert hervorragend:
SELECT x.id, y.val
FROM x
JOIN (SELECT *, lead(id, 1, 2147483647) OVER (ORDER BY id) AS next_id FROM y) y
ON x.id >= y.id
AND x.id < y.next_id
ORDER BY 1;
Die Fensterfunktion lead()
ist instrumental. Ich nutze die Option, einen Standard bereitzustellen, um den Eckfall der letzten Zeile abzudecken:2147483647 ist die größtmögliche Ganzzahl
. An Ihren Datentyp anpassen.
3) Sehr einfach und fast genauso schnell
SELECT x.id
,(SELECT val FROM y WHERE id <= x.id ORDER BY id DESC, val LIMIT 1) AS val
FROM x;Normalerweise korrelierte Unterabfragen sind eher langsam. Aber dieser kann einfach einen Wert aus dem (deckenden) Index auswählen und ist ansonsten so einfach, dass er mithalten kann.
Der Zusatz ORDER BY Artikel val (fette Hervorhebung) scheint sinnlos. Aber das Hinzufügen überzeugt den Abfrageplaner davon, dass es in Ordnung ist, den mehrspaltigen Index y_mult_idx zu verwenden von oben, weil die Sortierreihenfolge übereinstimmt. Beachten Sie die
im EXPLAIN Ausgabe.
Testfall
Nach einer lebhaften Debatte und mehreren Aktualisierungen habe ich alle bisher geposteten Anfragen gesammelt und einen Testfall für einen schnellen Überblick erstellt. Ich verwende nur 1000 Zeilen, damit SQLfiddle bei den langsameren Abfragen keine Zeitüberschreitung hat. Aber die Top 4 (Erwin 2, Clodoaldo, a_horse, Erwin 3) skalieren in allen meinen lokalen Tests linear. Nochmals aktualisiert, um meine neueste Ergänzung einzubeziehen, jetzt Format und Reihenfolge nach Leistung zu verbessern:
Big SQL Fiddle Leistung vergleichen.