In diesem Hadoop-Tutorial , werden wir Ihnen eine vollständige Einführung in MapReduce Key Value Pair geben.
Zunächst werden wir besprechen, was ein Schlüssel-Wert-Paar in Hadoop ist und wie ein Schlüssel-Wert-Paar in MapReduce generiert wird. Abschließend erklären wir die Generierung von Schlüssel-Wert-Paaren in MapReduce anhand von Beispielen.
Was ist ein Schlüssel-Wert-Paar in Hadoop?
Das Schlüssel-Wert-Paar in MapReduce ist die Datensatzentität, die Hadoop MapReduce zur Ausführung akzeptiert.
Wir verwenden Hadoop hauptsächlich zur Datenanalyse. Es befasst sich mit strukturierten, unstrukturierten und halbstrukturierten Daten. Wenn das Schema mit Hadoop statisch ist, können wir direkt an der Spalte statt am Schlüsselwert arbeiten. Aber wenn das Schema nicht statisch ist, arbeiten wir an einem Schlüsselwert.
Der Schlüsselwert ist nicht die intrinsische Eigenschaft der Daten. Aber sie werden vom Benutzer ausgewählt, der die Daten analysiert.
MapReduce ist die Kernkomponente von Hadoop, die Datenverarbeitung bereitstellt. Es führt die Verarbeitung durch, indem es den Job in zwei Phasen aufteilt:Zuordnungsphase und Reduzierungsphase . Jede Phase hat einen Schlüsselwert als Input und Output.
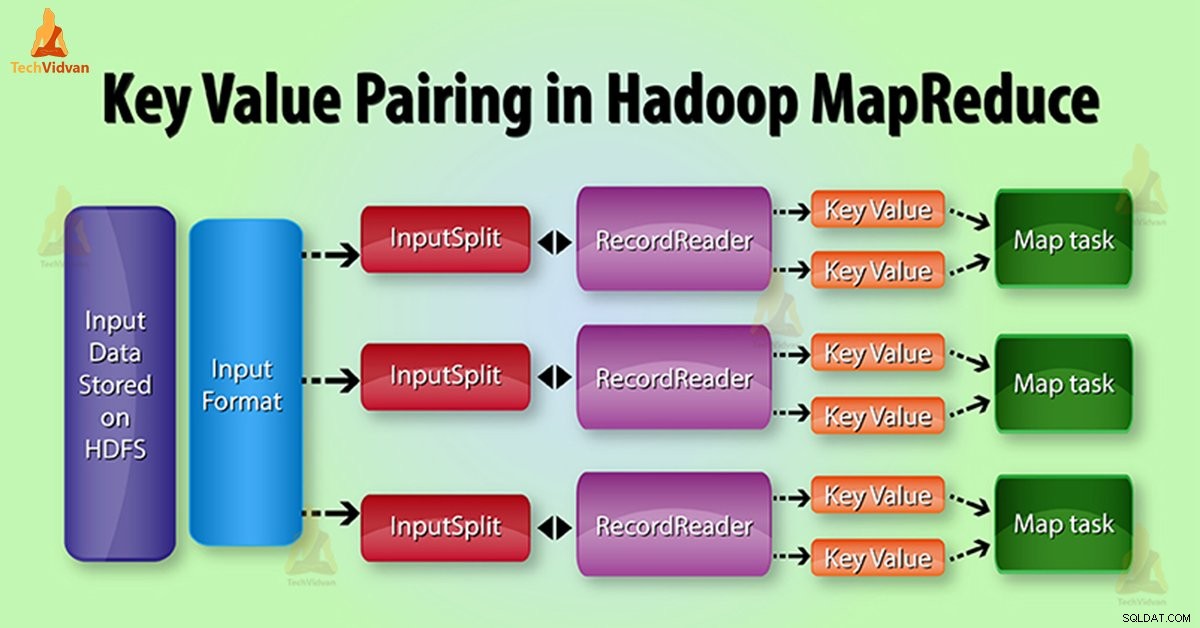
Generierung von MapReduce-Schlüsselwertpaaren in Hadoop
Bei der Ausführung von MapReduce-Jobs, bevor Daten an den Mapper gesendet werden , wandeln Sie es zuerst in Schlüssel/Wert-Paare um. Weil Mapper nur Schlüssel-Wert-Paare von Daten.
Das Schlüssel-Wert-Paar in MapReduce wird wie folgt generiert:
InputSplit – Es ist die logische Darstellung von Daten, die InputFormat erzeugt. Im MapReduce-Programm beschreibt es eine Arbeitseinheit, die eine einzelne Kartenaufgabe enthält.
RecordReader – Er kommuniziert mit dem InputSplit. Danach konvertiert er die Daten in Schlüssel-Wert-Paare, die zum Lesen durch den Mapper geeignet sind. RecordReader verwendet standardmäßig TextInputFormat, um Daten in Schlüsselwertpaare umzuwandeln.
Bei der Ausführung des MapReduce-Jobs verarbeitet die Map-Funktion ein bestimmtes Schlüssel-Wert-Paar. Gibt dann eine bestimmte Anzahl von Schlüssel-Wert-Paaren aus. Die Funktion „Reduzieren“ verarbeitet die Werte, die nach demselben Schlüssel gruppiert sind.
Gibt dann einen weiteren Satz von Schlüssel-Wert-Paaren als Ausgabe aus. Die Map-Ausgabetypen sollten wie unten gezeigt mit den Eingabetypen des Reduzierens übereinstimmen:
- Karte: (K1, V1) -> Liste (K2, V2)
- Reduzieren: {(K2, Liste (V2}) -> Liste (K3, V3)
Auf welcher Grundlage wird ein Schlüssel-Wert-Paar in Hadoop generiert?
Die Generierung von Schlüssel-Wert-Paaren von MapReduce hängt vollständig vom Datensatz ab. Hängt auch von der benötigten Leistung ab. Framework spezifiziert Schlüssel-Wert-Paare an 4 Stellen:Eingabe/Ausgabe zuordnen, Eingabe/Ausgabe reduzieren.
1. Karteneingabe
Die Karteneingabe verwendet standardmäßig den Zeilenversatz als Schlüssel. Der Inhalt der Zeile ist Wert als Text. Wir können sie modifizieren; indem Sie das benutzerdefinierte Eingabeformat verwenden.
2. Kartenausgabe
Die Karte ist dafür verantwortlich, die Daten zu filtern. Es bietet auch die Umgebung, um die Daten auf der Basis von Schlüsseln zu gruppieren.
- Schlüssel– Es ist das Feld/der Text/das Objekt, auf dem die Daten gruppiert und auf dem Reduzierer aggregiert werden .
- Wert– Es ist das Feld/der Text/das Objekt, das jeder einzelne Methodenhandle reduziert.
3. Eingaben reduzieren
Kartenausgabe ist Eingabe zum Reduzieren. Es ist also dasselbe wie Map-Output.
4. Ausgabe reduzieren
Es hängt ganz von der erforderlichen Leistung ab.
MapReduce-Schlüsselwertpaar-Beispiel
Zum Beispiel der Inhalt der Datei, die HDFS Geschäfte sind Chandler is Joey Mark is John . Also definieren wir jetzt durch die Verwendung von InputFormat, wie diese Datei aufgeteilt und gelesen wird. Standardmäßig verwendet RecordReader TextInputFormat, um diese Datei in ein Schlüssel-Wert-Paar zu konvertieren.
- Schlüssel – Es ist der Offset des Zeilenanfangs innerhalb der Datei.
- Wert – Es ist der Inhalt der Zeile ohne Zeilenabschlusszeichen.
Hier,Schlüssel ist 0 und Wert ist Chandler ist Joey Mark ist John.
Schlussfolgerung
Zusammenfassend können wir sagen, dass der Schlüsselwert nur eine Datensatzentität ist, die MapReduce zur Ausführung akzeptiert. InputSplit und RecordReader generieren ein Schlüssel-Wert-Paar. Daher ist der Schlüssel der Byte-Offset und der Wert der Inhalt der Zeile.
Ich hoffe, Ihnen hat dieser Blog gefallen. Wenn Sie Vorschläge oder Fragen zu MapReduce-Schlüsselwertpaaren haben, hinterlassen Sie bitte einen Kommentar in einem der unten angegebenen Abschnitte.



